题外话
听学长指示闻着味就过来了体验以后觉得不错,roadmap.sh非常适合入门学习,而且是交互式的,推荐用于某项技能的入门基础快速学习,但是要注意是 全英文 的,不想啃就开翻译插件吧
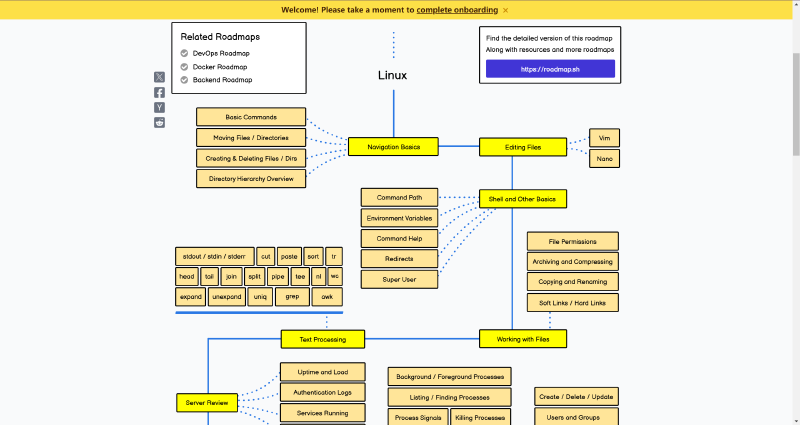
basics navigation
commands and basical knowledge
navigation basics
Basic commands
cd: change directoryls: list files and direrctories in the current directorypwd: view working directoryman: view manual page for a command(查看某个指令的详解)
files and directories
- 创建文件
touch: 在linux中用touch命令创建空文件touch newfile.txtcat:cat > newfile.txt如果不存在newfile.txt则创建,存在则覆盖
- 移动文件
mv:mv [options源文件] source destinationsource表示要移动的文件或目录,而destination表示目标位置
- 删除文件
rm:rm example.txt永久性删除,如果想在删除前确认,可以使用-i选项:rm -i example.txtrmdir:rmdir [directory]删除目录
Understanding Directory Hierarchy
在Linux中,了解目录层次结构是非常重要的。
linux系统的目录结构也称为 文件系统层次结构标准,即 FHS,它是一种定义的树结构,有助于防止文件分散在整个系统中,并且易于导航和组织。
- /:根目录,文件系统的顶层
- /home:用户主目录
- /bin:二进制文件目录,包含常用的系统命令
- /sbin:系统二进制文件目录,包含系统管理员使用的命令
- /etc:系统配置文件目录
- /var:可变数据(日志、假脱机文件)
- /tmp: 临时文件目录
- /usr:用户应用程序和数据目录
- /lib:共享库
Editing Files
与其他操作系统一样,Linux允许出于多种目的编辑文件,无论您是需要配置某些系统功能还是编写脚本。Linux 默认提供多种文本编辑器,包括:
nanovi/vimemacs gedit
每个编辑器都有自己的学习曲线和命令集
例如,nano是一个简单的文本编辑器,它易于使用,非常适合简单的文本编辑。vi/vim则在另一方面,更为先进,提供广泛的功能和命令(老一辈的游刃有余) 要编辑文件首先要使用以下命令
| |
Vim:编辑文件的基本工具
Vim(Vi Improved)是一款功能强大且灵活的文本编辑器,用于类 Unix 系统。它以原始 Vi 编辑器为基础,并添加了其他功能和改进,包括多级撤消、语法突出显示和大量用于文本操作的命令集。(虽然学起来很麻烦就是了)
Vim主要以三种模式运行:
- Normal(for navigation and manipulation).
- Insert(for editing text).
- Command(for running commands).
要插入新内容,使用i进入插入模式,然后输入内容。
编辑完成后,按ESC键退出插入模式,然后输入:wq保存并退出。
当然Vim的操作远不止这些
Nano:简单的文本编辑器
Nano相对来说是更为流行、对用户来说友好的文本编辑器,用于直接在 Linux命令行界面(CLI Linux Command Line Interface) 中编辑文件。是一个vi和emacs的替代品。对初学者来说更为简单实用,介绍一些针对流行的Linux发行版的安装方式(一般来说很多发行版是自带的)
| |
Shell and Other Basics
Linux Shell是一个命令行界面,用于与操作系统进行交互。
shell 有助于简化系统命令,并充当用户和系统内核之间的中介界面。shell 可以高效快速地执行复杂任务。
Linux中有多种shell,包括:Bourne shell(sh)、C shell(csh)、Bourne-Again Shell(bash)等。
Command Path in Shell Basics
Simply put, command path is a variable that is used by the shell to determine where to look for the executable files to run.
通常,shell需要知道命令的可执行文件的绝对路径才能运行它,而 command path 允许shell自动按正确顺序搜索指示的目录。这些路径存储在 $PATH环境变量中。echo $PATH将返回shell按顺序搜索的所有目录,以查找要运行的命令

Environment Variables
在Linux中,环境变量是 动态命名 的值,可以影响 shell 中正在运行的进程的行为。
它们存在于每个shell的进程当中,一个shell的进程的环境变量包括但不限于
user’s home directory, command search path, terminal type, and program preferences.
环境变量有助于实现 Unix 系统中灵活的自定义。它们提供了一种在 Linux 中的多个应用程序和进程之间共享配置设置的简单方法。
可以使用 env命令列出shell会话中的所有环境变量,如果想查看某个特定的变量,则可以使用echo $PATH命令
| |
具体地学习以及 实验 可见Linux环境变量
Command Help
上文就有提到,在Linux中学会使用命令帮助非常重要,它能使用户轻松浏览Linux Shell命令。
例如:man [command]可以在任何命令钱调出其手册条目,其中解释了该命令的作用、语法、可用选项help [command]选项也可以显示命令的可用选项和用法。更适合shell内置函数,对每个函数进行简要描述。
可见获取Linux命令帮助
以及如何使用手册页
Redirects
Linux的shell为user提供了一种管理命令/程序的输入和输出流的强大方法,称为 重定向。
Linux是一个多用户和多任务操作系统,每个进程通常打开3个流:
- 标准输入(stdin):默认情况下,从键盘读取输入。
- 标准输出(stdout):默认情况下,将输出写入屏幕。
- 标准错误(stderr):默认情况下,将错误消息写入屏幕。
Linux的重定向功能便于我们操作流,从而提高运行命令/程序的灵活性。除了默认设备(键盘啦终端啦)外, I/O流可以重定向到其他文件/设备。
例如,如果想将命令输出存储到文件中而不是打印到控制台,可以使用">“运算符号
| |
将"ls -al"的输出写入了txt中,如果已存在该文件就覆盖
experiment
&&运算符
该运算符用于将多个命令链接在一起,并仅在第一个命令成功执行时才执行第二个命令,对于有依赖的命令链接很有用

||运算符
当第一个命令失败时才执行第二个命令。这对于提供后备选项或错误消息很有用。
»追加输出重定向符号
如果我们想要附加信息的话,可以使用”»“运算符,它将命令的输出附加到文件中,而不是覆盖现有内容。
| |
|管道运算符
管道运算符将一个命令的输出作为另一个命令的输入。这对于将一个命令的输出传递给另一个命令进行处理非常有用。
例如
| |
- echo命令将字符串"apple banana cherry date elderberry"输出到标准输出
- tr命令将空格字符转换为换行符,每个水果名称都单独一行
- sort命令将输出按字母顺序排序
于是有这样的输出:

最后我们综合一下这些技术来创建一个文件,搜索特定单词,然后重定向输出:
| |
结果会是什么样的?可以自己想一下
Superuser
超级用户,也称为“root 用户”,是 Linux 中拥有广泛权力、特权和功能的用户帐户。此用户可以完全控制系统并可以访问存储在系统上的任何数据。这包括修改系统配置、更改其他用户的密码、安装软件以及在 shell 环境中执行更多管理任务的能力。
用su或sudo命令切换到超级用户,sudo允许我们以另一个用户身份运行命令,默认为root。还有一个关键区别:sudo会记录用户执行的命令,而su不会。
Working with Files
处理文件是Linux的重要组成部分,就在上面,我们学习了Linux 终端中用于文件处理的一些基本命令包括touch创建文件、mv移动文件、cp复制文件、rm删除文件以及ls列出文件和目录。
接下来我们还要具体学习一部分文件操作
File Permissions
三种用户: owners, groups, and others who can have a different set of permissions.
看一个例子:
| |
第一个-表示这是一个文件,如果是d则表示这是一个目录。接下来的9个字符表示权限,每3个字符一组,分别代表owner, group, and others的权限。(懒得写了)
Archiving and Compressing
Linux提供了强大归档实用程序,用于将文件和目录打包到单个文件中,以便于传输或备份。
主要工具有tar和gzip以及bzip2
- tar:是一种多功能工具,可以管理和组织文件到一个文档中。
- gzip和bzip2
| |
experiment
我们来实践一下,在~/Linux_study下
| |
可以看到
| |
让我们用tar打包:tar -cvf tar_archive.tar tar
-c选项表示创建一个新归档文件,-v选项表示详细模式(可选),-f选项表示指定归档文件的名称。
要查看内容而不提取,可以使用:tar -tvf tar_archive.tar:-t是详细列出,-f指定了文件,-v表示列出内容
要提取文件内容,我们可以这么做:
| |
-x选项表示提取归档文件的内容,
-C选项表示指定提取目录,告诉tar提取之前更改extracted_tar为当前目录
| |
接下来我们用命令gzip来压缩它:gzip tar_archive.tar
现在我们可以看到tar_archive.tar.gz文件,用ls -lh tar_archive.tar.gz可以看到它的大小234字节
打包和压缩的区别
- Packaging
- 目的:将多个文件和目录合并为一个文件。
- 功能:分组文件
- 工具:
tar - 结果:档案的总大小通常略大于其中所有文件的大小总和。
- Compression
- 目的:减小文件的大小。
- 功能:应用算法消除数据中的冗余
- 工具:
gzip和bzip2 - 结果:压缩后的文件通常比原始文件小,使用前需解压 如下:
| |
Copy and Renaming
- cp:
cp /path/to/original/file /path/to/copied/file指定文件和目标路径 - mv:
mv /path/to/original/file /path/to/moved/file
指定要重命名或移动的文件和要重命名或移动到的文件和路径 - 重命名:
如我们要将
index.html重命名为home.html:
| |
- 移动多个文件
| |
实现了将所有js文件移动到scripts目录下
安全转移:使用
-i选项1mv -i *.js scripts/enter后将会收到消息:
1mv: overwrite 'scripts/file1.js'? n输入n后就不会覆盖了
Soft links/Hard links
- 硬链接:指向文件系统中的同一物理位置,可以理解为 镜像,源文件删除后硬链接仍存在
- 软链接:指向文件系统中的另一个位置,可以理解为 快捷方式
- 创建硬链接:
ln /path/to/original/file /path/to/link - 创建软链接:
ln -s /path/to/original/file /path/to/link - 删除链接:
rm /path/to/link
Text Processing
文本处理是系统管理员和开发人员的一项基本任务。Linux 是一个强大的操作系统,它提供了强大的文本搜索、操作和处理工具。
用户可以使用awd sed grep cut等命令进行文本过滤、替换和处理正则表达式。shell脚本、python等编程语言都可以在Linux实现出色的文本处理功能
当然还有vim nano等文本编辑器
非常 非常关键
以下部分不做实验,只举少量例子
资源:Linux Filters
Linux Text Processing
stdin/stdout/stderr
Linux 中 stdout 和 stderr 的概念属于 Linux 文本处理的基础,在 Linux 中,程序执行时一般会开启三个通信通道,分别是 STDIN(标准输入)、STDOUT(标准输出)、STDERR(标准错误)。
通道(channels)都有特殊的功能 STDOUT会发送大多数shell命令输出的通道 STDERR专门用于发送错误信息
示例
| |
>将stdout重定向到stdout.txt中
2>则将stderr重定向到stderr.txt中,正确输出和错误信息将存储在不同文件中检查和处理
cut
剪切命令允许我们从文件或输出中剪切出每行的部分,并将其显示在标准输出(通常是终端)上。它通常用于scripts和pipe,尤其是用于文件操作和文本操作。 我们需要某个特殊部分的时候这个指令会很有用
| |
示例
| |
此命令以逗号分隔,输出第二个字段也就是
two
paste
| |
在 Linux 中,paste 是一个功能强大的文本处理实用程序,主要用于合并来自多个文件的行。它允许用户按列而不是行合并数据,为文本数据处理增加了极大的灵活性。用户可以选择特定的分隔符来分隔列,从而提供多种方式输出。
示例

| |
sort
Linux 提供了多种处理和操作文本文件的工具,其中之一就是 sort 命令。Linuxsort中的该命令用于逐行对文本文件的内容进行排序。该命令使用 ASCII 值对文件进行排序。可以使用此命令以多种不同的方式对文件中的数据进行排序,例如按字母顺序、数字顺序、反向顺序甚至按月排序。sort 命令将文件作为输入,并在stdout上打印排序后的内容。
| |
一般会用重定向
复杂一点的:
| |
- -n 决定按Numeric排序 (-nr加上r就会逆向派)
- -t: 指定字符以冒号分隔
- -k2 使用第二个字段作为排序键 见sort命令
tr
用于翻译或替换字符,从标准输入读入并写入标准输出。虽然翻译多用,但是功能实际上很多,比如用于替换一组符号,删除或压缩重复字符 用法
示例
| |
实现了将小写a-z替换为大写A-Z 见tr命令
head & tail
head允许用户输出文件的头部,通常用于预览文件开头,这可以快速检查超大文件中的数据,通常将每个文件的前10行打印到标准输出
| |
也可以自定义输出行数
| |
tail命令用于输出文件最后部分,将最后的N字节、行、块、字符或单词打印到标准输出
join(我不怎么会用)
join允许我们在一个公告字段上合并文件的行,就类似SQL中的“join”,处理大量数据时特别管用,用于两个文件中的行来形成包含以有意义的方式关联的行对的行
注意!只有文件排序后,该命令才能正常工作 见join命令
Split
于将大文件拆分为小文件的命令,顾名思义。Linuxsplit中的命令根据用户指定的行或字节将文件分成多个相等的部分。
由于其实用性,它是一个有用的命令。例如,如果您有一个大型数据文件,由于其大小而无法有效使用,则可以使用 split 命令将文件拆分为更易于管理的部分。
基本语法
| |
默认情况下Split会将文件分成几个较小的文件,每个文件1000行,如果没有提供输入文件,或输入文件为-,它会从标准输入读取
例如有一个bigfile.txt要拆分为一个个有500行的文件,命令如下:
| |
pipe
没错,熟悉的管道命令,用于Linux中连接两个或多个命令的强大功能,允许将一个命令通过pipe作为另外一个的输入。对于文本处理尤其有用,一个简单的例子
| |
ls列出文件,grep获取目录下文件并过滤掉不以.txt结尾的文件
nl
对于文本中要编号行数有用,number lines,如果你需要概览某一部分也可以用到这个指令,nl只会读到非空行,当然也可以根据命令进行修改
| |
- -b a便会对所有行进行编号 如果没有指定文件,nl命令会等待用户的标准输入 见nl
wc
word count
用于计算数量,可以是字节数、符号数、词数、行数,当然不止可以读行数,还可以跟踪程序输出,计算代码行数等,是 用于大规模文本分析和精密分析的宝贵工具
| |
expand/unexpand
是一个Unix和类Unix操作系统中的一个命令行实用程序,可将制表符转换为空格
emmm,有了这个命令可以减轻制表符所带来的扰乱格式,使用linux shell脚本时就很有用,制表符空格在不同系统或文本编辑器上可能有不同格式会不一致,这样使用大大提高代码可读性
该expand命令默认将制表符转换为 8 个空格。以下是示例用法:
| |
在此示例中,filename是要将制表符转换为空格的文件的名称。运行该命令后,制表符转换后的内容将打印到标准输出。
要指定每个制表符的空格数,-t可以使用以下选项:
| |
在此示例中,每个制表符filename将被替换为 4 个空格。然后输出将显示在控制台上。
unexpand就是相反的操作
uniq
用于过滤重复的行,来帮助检查和处理文本文件。无论处理的是数据列表还是大型文本文档,该uniq命令都允许您查找和过滤重复的行,甚至可以提供文件中每个唯一行的计数。重要的是要记住,uniq只会删除彼此相邻的重复项,因此为了充分利用此命令,通常sort首先使用该命令对数据进行排序。
使用示例uniq为:
| |
在此示例中,names.txt是一个包含名称列表的文件。该sort命令对文件中的所有行进行排序,然后uniq删除所有重复的行。结果输出将是 中的唯一名称列表names.txt。
见uniq
grep💖
LINUX三剑客,grep awk sed
grep全局正则表达式打印)被认为是类 Unix 操作系统(包括 Linux)文本处理领域的重要工具。它是一款功能强大的实用程序,可以搜索和过滤与给定模式匹配的文本,当它识别出与模式匹配的行时,会将该行打印到屏幕上
grep 是许多 shell 脚本、bash 命令和命令行操作的重要组成部分,它是一种多功能工具,每个 Linux 发行版都预装了它。它包含三个主要部分 - 格式、操作和正则表达式。
另一种选择——
ripgrep,支持grep所有功能并进行扩展
| |
常用
-i:忽略大小写进行匹配。-v:反向查找,只打印不匹配的行。-n:显示匹配行的行号。-r:递归查找子目录中的文件。-l:只打印匹配的文件名。-c:只打印匹配的行数。
学习grep和正则表达式
见grep命令
可以看博客园的这篇文章
正则表达式概述
.(点)- 单个字符。?前一个字符仅匹配 0 次或 1 次。-前面的字符匹配 0 次或更多次。+- 前面的字符匹配 1 次或多次。{n}- 前一个字符恰好匹配 n 次。{n,m}- 前一个字符匹配至少 n 次,但不超过 m 次。[agd]- 该字符是方括号内的字符之一。[^agd]- 该字符不是方括号内的字符之一。[cf]- 方括号内的破折号表示范围。在这种情况下,它表示字母 c、d、e 或 f。()- 允许我们将多个字符分组为一个字符。|(管道符号)——逻辑或运算。^- 匹配行的开头。$- 匹配行尾。
awk
三剑客之二awk
awk 是一种功能强大的文本处理语言,广泛用于类 Unix 操作系统,包括 Linux。awk 以其三位原始开发者 Alfred Aho、Peter Weinberger 和 Brian Kernighan 的名字命名 该语言由脚本中的一组命令组成,本质上,awk 逐行读取输入文件,识别与脚本中指定的模式相匹配的模式,然后根据这些匹配执行动作。 下面是如何使用 awk 打印文件每行的前两个字段的示例:
| |
这将显示“filename”中每一行的第一个和第二个字段(通常用空格分隔) 见awk命令 c
sed
三剑客之三sed
- 格式:
sed [options] '[地址定界] command' file(s)
sed是一种流编辑器,一次处理 一行 把当前处理的行存储在临时缓冲区作为patternspace,接着会用sed命令进行缓冲区内容处理并输出在屏幕后读取下一行直到末尾并且不重定向输出或-i就不会对文件修改 - 功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作
常用选项
- -n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
- **-e:**多点编辑,对每行处理时,可以有多个Script
- -f:把Script写到文件当中,在执行sed时-f 指定文件路径,如果是多个Script,换行写
- -r:支持扩展的正则表达式
- -i:直接将处理的结果写入文件
- -i.bak:在将处理的结果写入文件之前备份一份
地址定界
- 不给地址:对全文进行处理
- 单地址:
- #: 指定的行
- /pattern/:被此处模式所能够匹配到的每一行
- 地址范围:
- #,#
- #,+#
- /pat1/,/pat2/
- #,/pat1/
- ~:步进
- sed -n ‘1~2p’ 只打印奇数行 (1~2 从第1行,一次加2行)
- sed -n ‘2~2p’ 只打印偶数行
编辑命令
- d:删除模式空间匹配的行,并立即启用下一轮循环
- p:打印当前模式空间内容,追加到默认输出之后
- a:在指定行后面追加文本,支持使用\n实现多行追加
- i:在行前面插入文本,支持使用\n实现多行追加
- c:替换行为单行或多行文本,支持使用\n实现多行追加
- w:保存模式匹配的行至指定文件
- r:读取指定文件的文本至模式空间中匹配到的行后
- =:为模式空间中的行打印行号
- !:模式空间中匹配行取反处理
- s///:查找替换,支持使用其它分隔符,如:s@@@,s###;
- 加g表示行内全局替换;
- 在替换时,可以加一下命令,实现大小写转换
- \l:把下个字符转换成小写。
- \L:把replacement字母转换成小写,直到\U或\E出现。
- \u:把下个字符转换成大写。
- \U:把replacement字母转换成大写,直到\L或\E出现。
- \E:停止以\L或\U开始的大小写转换
演示
常用选项
| |
地址界定
| |
tee
Linux tee命令用于读取标准输入的数据,并将其内容输出成文件。(就是打印输出同时存入文件)
tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件。
在pwncollege的考察中我们知道,tee实际上实现的是复制数据流
借助tee,我们可以同时实现让多个文件接受输出command1 | tee >(command2) >(commannd3)
>()会实现一个进程的替换,>(command2)实际上创建了一个文件描述符"/dev/fd/63"类似于这样
obj文件(目标文件或可执行文件)——odjdump
在Linux环境下,我们可以使用objdump命令对目标文件(obj)或可执行文件进行反汇编,它以一种可阅读的格式让你更多的了解二进制文件可能带有的附加信息。
| |
xxd
xxd是Linux下命令行工具,用于将文件或数据转换为十六进制格式显示,还可以将十六进制数据重新转化为二进制文件
功能:调试、文件内容分析、数据转化
- 语法格式:
xxd [options][inputfile[outputfile]] - options:
--r:十六进制->二进制(反向操作) --p/-ps:以连续纯十六进制(不带偏移地址和ascii)输出 --s offset-l length两者经常搭配使用,前者指定从偏移位置开始读取(负数则是末尾)后者显示指定长度的字节
strace
一个强大的 Linux 调试工具,用于跟踪进程执行时的系统调用和信号。它能详细记录进程对系统调用的使用情况,包括参数、返回值、时间消耗等
我们需要动态跟踪程序进程时便可以使用
跟踪进程
strace ls -lh /var/log/messages 会跟踪 ls...这条命令的执行过程并输出所有的系统调用
- 跟踪已经在进行的进程:指定PID
strace -p 17553 - 重定向到文件:
strace -o strace_output.txt ls -lh /var/log/messages
server review
在审查 Linux 服务器的过程中需要包括评估服务器的性能、安全性和配置,以确定需要改进的地方或任何潜在问题。审查范围可以包括检查安全增强功能、检查日志文件、查看用户帐户、分析服务器的网络配置以及检查其软件版本。 Linux以其稳定性和安全性闻名,已成为全球许多网络和服务器后端的必备软件。根据使用的发行版,Linux 提供了多种工具和命令来执行全面的服务器审查。
| |
authentication logs
在处理 Linux 服务器及其维护时,需要定期检查的最重要组件之一是身份验证日志。这些日志通常位于 /var/log/auth.log(适用于基于 Debian 的发行版)或 /var/log/secure(适用于 Red Hat 和 CentOS),记录服务器上发生的所有与身份验证相关的事件和活动。其中包括系统登录、密码更改和发出的 sudo 命令等。
身份验证日志是监控和分析 Linux 服务器安全性的宝贵工具。它们可以指示暴力登录攻击、未经授权的访问尝试以及任何可疑行为。定期分析这些日志是确保服务器安全性和数据完整性的一项基本任务。
下面是如何使用tail命令查看身份验证日志的最后几个条目的示例:
| |
熟悉阅读和理解身份验证日志,因为这是确保服务器安全的重要方法之一。
system services
Linux 服务器因其稳定性和灵活性而广受欢迎,这些因素使其成为企业和组织在管理各种服务时的首选。在 Linux 服务器下运行的服务包括 Web 服务、数据库服务、DNS 服务器、邮件服务器等。
作为 Linux 系统管理员,定期检查这些正在运行的服务以管理资源、检查其状态和解决问题非常重要,从而确保服务器的健康和性能。
Linux 有多种工具可以实现这一点,例如:systemctl service netstat ss lsof
例如,该命令systemctl在 Linux 系统上广泛用于列出所有正在运行的服务:
| |
此命令将显示所有活动服务及其当前状态的列表。它是服务器管理的必需品,应该是任何 Linux 系统管理员工具箱的一部分。
process management
进程管理是任何操作系统不可或缺的一部分,Linux 也不例外。在 Linux 上运行的每个程序(无论是应用程序还是系统操作)都被视为进程。这些进程执行不同的任务,但协同工作以提供无缝的操作体验。
在 Linux 中,用户可以使用不同的命令来交互和管理这些进程,以执行各种进程管理任务,例如查看当前正在运行的进程、终止进程、更改进程的优先级等。了解这些命令以及如何有效地使用它们对于 Linux 进程管理至关重要。
例如,ps 命令提供有关当前正在运行的进程的信息:
| |
这将列出所有当前正在运行的进程,其中包含进程 ID、运行该进程的用户、其消耗的 CPU 和内存、启动该进程的命令等信息。
top是另一个常用命令。它提供系统当前状态的实时更新视图,包括进程:
| |
另一个强大的工具是kill,它可以向进程发送特定信号。例如,你可以使用SIGTERM(15) 正常停止进程,或使用 (9) 强制停止进程SIGKILL:
| |
list/find processes
文件系统proc是一个强大的工具
具体来说它提供有关正在运行的进程的详情信息,包括PID、状态和资源消耗
我们也可以通过探索proc目录(/proc),我们可以深入了解和查看系统内核参数和每个进程的具体系统详细信息
| |
process SIGNALS
即 进程信号,这是Unix和Linux系统中的一种通信机制,它们提供了一种通知进程同步或异步时间的方法。
有多种信号可用,比如SIGINT、SIGSTOP、SIGKILL等,可将其发送到正在运行的进程来中断、暂停或终止
例如,向PID12345进程发送stop信号
| |
这里再讲一下kill命令
| |
Linux中的kill是用于手动终止进程的内置命令,用kill基本是请求进程暂停、停止
process priorities
Linux内核在proc结构中队进程进行排序,通常位于/proc文件系统目录下。此结构包含有关所有活动进程信息,也包括了优先级
优先级从-20到+19
通过了解和管理进程优先级,我们可以优化系统性能并控制哪些进程获得更多/更少的CPU关注
看一个简单命令,用于显示所有进程的ID、优先级和用户
| |
需更改任何进程的优先级,可以用renice命令
| |
process Forking
forking在Linux进程管理中非常常见,它进行了对一个进程自身的复制(子进程),并且允许几个进程并发进行执行,fork的进程几乎是完全一致的除了PID等少数的值 来个C的源码
| |
fork成功就会返回进程ID
User Management
可参考文章usermanager
前言:
Linux的开放式系统有一个用户管理系统,使得可以有大量用户进行跟系统的交互。
在Linux中会进行用户角色、分配权限、组、所有权和其他相关方面的交互,我们需要牢记,如果作为Linux管理员尤其
为了使操作更流畅可控,Linux中的user操作包括creating deleting modifying等等,也包括了为用户/组分配文件和目录的权限和所有权
我们通过基本的shell命令对Linux用户进行管理
用户
例如我们创建一个用户:
| |
如果没有sudo就会出现permission denied
为了验证我们可以
| |
我们会看到类似输出:
| |
这里解释一下
- 用户名:fumofumo
- 密码:x(实际存储在别处)
- 用户ID:1001
- 组ID:1001
- 主目录:/home/fumofumo(这里没有创建)
- 默认shell:/bin/sh
创建有主目录的用户
接下来我们创建并给用户提供一个主目录
| |
-m提供了创建主目录的命令
可以用下面的命令来验证
| |
通过sudo passwd为其创建一个密码
通过sudo userdel -r删除用户
Users and Groups
Linux用户中的用户管理使用用户组高效管理系统用户和权限
每个用户都有一个主组和一个或多个附加组,可以通过groupadd goupdel groupmod等命令来管理组
组
| |
Service Management
Service Management是Linux系统管理的一个重要方面,涉及到安装、配置、监控和维护系统服务和守护进程。Linux系统通常运行多个服务和守护进程,这些服务和守护进程在后台执行任务并提供功能,例如Web服务器、数据库服务器、文件服务器等。 现代Linux发行版中服务管理通常由systemd处理
Checking Service Status
| |
这是一个检查服务状态的命令,systemctl是systemd的命令行工具,apache2.service是要检查的服务名称
该命令可以提供有关Apachw2服务器的状态信息,通过高效管理服务状态,Linux管理员可以诊断和纠正问题
start/stop service
| |
务必使用sudo进行操作,这些命令在不同发行版或有不同
Checking logs
检查日志在系统管理和故障排除过程中至关重要
日志中包含系统进程/用户/管理员生成的一些重要日志/var/log.可以使用多个命令访问和查看日志.例如,dmesg可以使用命令显示kernel ring buffer.多数情况下我们直接使用
| |
第一个命令将显示从启动到调用日志的整个系统日志,而第二个命令会显示特定服务运行状况
creating new service
在Linux中创建服务是指设置后台应用程序以实现运行并执行所需任务的过程.通常包括编写服务文件(即脚本),以指定如何使用服务管理系统启动,停止和重新启动服务.
例如可以简单创建一个test_service.service文件:
| |
然后将服务文件放在/etc/systemd/excutable来用ststemed识别它,注意,Linux的最佳实践规定,出于安全考虑,我们尽量不要用root运行,一般考虑新用户运行服务
Disk and Filesystems
Linux 使用各种文件系统来帮助我们存储和检索计算机系统硬件(例如磁盘)上的数据。文件系统定义了数据在这些存储设备上的组织、存储和检索方式。常见的 Linux 文件系统包括 EXT4、FAT32、NTFS 和 Btrfs。
每种文件系统都有其自身的优点、缺点和用例。例如,EXT4 通常用于 Linux 系统卷,因为它具有稳定性和与 Linux 的兼容性;而 FAT32 则可用于 USB 驱动器等可移动介质,因为它几乎兼容所有操作系统。
挂载硬盘时要尤其注意df -T进行查看
Inodes
inodes(索引节点)是文件系统中的一个核心概念 理解inode不仅有助于提高系统操作水平,还可以有助于我们理解 unix 的设计美学,即如何把底层复杂性抽象出简单概念
Inode是什么
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区”(Sector)512字节一个扇区(0.5KB)
操作系统读取硬盘,不会一个个扇区读取,这样效率太低,而是一个一个块(block)进行读取.
而由多个扇区组成的 块 就是文件读取的最小单位了.一般在4KB,即连续八个sector组成一block
文件数据这样存储了,我们还需要一个地方储存文件元信息.
as:
- 一些常规文件信息File type - regular file, directory, character device, etc
- 持有者
- 组
- 访问权限
- Timestamps 时间戳,包含mtime(上次文件修改时间)、ctime(上次属性更改时间)、atime(上次访问时间)
- 文件的硬链接数
- 文件大小
- 文件分配块数
- 文件指针(指向文件数据块)- 非常重要!
mounts
挂载系统,以mount source /mnt/**方式挂载文件系统、u盘等
adding disks
下是管理磁盘的常用命令:
- 用于
lsblk列出所有块设备(磁盘和分区)。 - 用于
fdisk /dev/sdX在磁盘上创建新分区。 - 用于
mkfs.ext4 /dev/sdX1在分区上创建新的文件系统。 - 用于
mount /dev/sdX1 /mount/point将文件系统挂载到目录。 具体方法可见
| |
swap
Linux中Swap用于物理内存(RAM)已满情况。如果系统需要更多内存,而物理内存已满,则内存中不活动页面移动到Swap,适用于虚拟内存。
拥有交换空间可确保系统物理内存不足时,可以将部分数据移动到Swap来释放RAM空间,但是会影响性能,因为基于磁盘的存储比 RAM 慢。
通常Swap会在两个地方:
- 自己的专有分区中
- 现有文件系统的常规文件中
可见Arch Wiki
LVM
Linux Logical Volume
一个设备映射器框架,为Linux内核提供逻辑卷管理。为了简化磁盘管理,允许使用abstracted storage divices作为逻辑卷而不是直接使用物理存储设备
LVM很灵活,可以调整卷大小、跨物理磁盘镜像卷、在磁盘间移动卷而无需关闭电源。
LVM 在 3 个级别上工作:Phisical Volumes (PV)、Volume Groups (VGS) 和Logical Volumes (LV)。
- PV 是实际的磁盘或分区。
- VG 将 PV 组合成单个存储池。
- LV 从 VG 中划分出部分内容供系统使用。
创建LVM
| |
由此实现创建一个物理卷/dev/sdb1,然后创建一个卷组my-vg。最后,我们从卷组中划分出一个10GB逻辑卷后将其命名为my-lv
据此,管理存储系统更加便利,可见CSDN LVM具体介绍
Windows不支持LVM,所以你不能在其上检测到LVM分区盘
Booting Linux
启动项,我们启动电脑系统的时候,system bootloader会加载到内存数据(回存放到固定位置)并根据选择我们启动指定的系统
这整个加载过程会包含一系列的阶段,
POST(Power-On Self Test) MBR(Master Boot Record) GRUB(引导启动界面系统)Kernel等等。最后我们就会加载进入GUI界面(或者通过命令行交互接口启动)
这里提供一个经典的GRUB配置,一般在/etc/default/grub
| |
这是一个最基本的启动Linux的Grub配置,但是根据不同的发行版和不同的需求配置启动的过程是相同的(说的就是你 F**k Nvidia)
Logs
Linux也会维护日志,以帮助管理员了解系统运行情况。日志记录了所有内容,包括用户活动、系统错误和内核信息。系统启动、加载和初始化关键系统组建时就尤为重要。
Linux的logs under booting是启动过程中生成的信息,记录了启动过程中生成的消息和信息。这些日志记录了系统启动期间发生的所有操作、事件供我们诊断系统行为。
Linux使用各种日志消息级别,从emerg(系统不可用)到debug(调试级别消息)。在启动过程中,系统将kernel init serve等各个组件的信息存储,看看juornalctl
可以使用dmesg查看启动消息,用于读取和打印kernel ring buffer。还有系统的日志设置来访问它们,日志中可见文件/var/log
你也可以sudo dmesg | less启动日志查看,less查看
Boot Loaders
引导加载程序将操作系统内核加载到系统内存中,内核才会初始化硬件组件和加载必要驱动程序,启动schedular调度程序来执行初始化进程。
GRUB是我现在使用的,也时常用的目前流行的Linux booting,并提供各式的特色像图形化界面、脚本加载、调试功能等等。
不管怎么样,对于你使用的引导加载程序的特点和与其他的不同点是要好好熟悉才是可以的
可见GNU GRUB 官网了解更多
Networking 🌟
LInux的网络功能通过各种管理工具建立了跨平台的系统连接和资源共享(所以服务器基本都使用的是Linux)。默认的配置存储在/etc/network/interfaces
关键的指令包括了ifconfig 或ip来进行接口管理,支持各种协议并且有非常优秀的拓展性,这对于系统的连接和网络故障排除都非常重要。Linux还支持基于文件的处理的网络配置方式,将一系列配置都通过文件来进行处理。比如/etc/network/interfaces或者/etc/sysconfig/network-scripts/等等,具体取决于发行版。以下是一些学习用链接(注意对于计算机来说最重要的是实践)
Linux网络综合指南
Linux 网络基础初学者指南
网络基础实践
(这个很好用)
TCP/IP Stack
即Transmission Control Protocol/Internet Ptorocol 传输控制协议和互联网协议
计算机网络通信的基础网络协议套件
分为四个基本层:
- Network Interface (网络接口层)
- Internet (互联网层)
- Transport(传输层)
- Application (应用层) Linux中,其为操作系统功能不可或缺的一部分。
详情
基本的家用网络有以下基本的不同组件
- ISP——互联网服务提供商,我们付费在家使用互联网的公司
- 路由器——允许网络上的设备连接到互联网,一般现代路由器支持 以太网线连接 和 无线网
- WAN WLAN LAN 广域网 无线局域网 局域网
我们在看几个实例之前,我们必须做一些非常boring。。。的术语
The OSI 即(Open Systems Interconnection)开放系统互联模型是一个网络理论模型。我们将会知道数据包是如何在 七个 不同的层级中进行传输的(没错就是大家都必须要学的计网基础口牙),OSI模型确切的存在并实际在我们如今使用的TCP/IP 协议中起到了必不可少的作用
收集,寻址,传输和路由方式——通过TCP/IP协议套件协同工作,我们逐步了解这些协议是如何工作的,从而详细展示数据包在网络中的传输流程
TCP/IP模型
四层网络介绍
应用层
顶层,决定计算机程序(web浏览器)如何与传输层服务进行交互以查看发送、接受的数据
- HTTP(超文本传输协议Hypertext Transfer Protocol)——互联网上的网页
- SMTP(简单邮件传输协议Simple Mail Transfer Protocol)——电子邮件传输
传输层 决定数据如何传输,包括检查正确端口、数据完整性以及基本传输数据包
- TCP(传输控制协议Transport Control Protocol)——保证可靠的数据传输
- UDP(用户数据包协议 User Detapack Protocol)——不可靠的数据传输
网络层
指定如何在主机以及网络之间进行包传输
- IP(互联网协议Internet Protocol)——帮助数据包从一台机器路由到另一台(选择路径)
- ICMP(互联网控制消息协议Internet Control Message Protocol)——帮助我们了解错误信息、调试信息等实时信息
链路层
指定了如何在物理硬件之间发送数据。例如,数据通过以太网、光纤等传输
然后在我们深入探讨之前,聊一聊网络寻址。
在我们发送数据包时,我们必须知道它寄给谁以及它来自哪里。我们的主机和其他主机使用MAC地址(Media Access Control)以及IP地址来进行识别
网络寻址
MAC地址
MAC地址,硬件地址唯一标识符,不会发生改变。也就是对应着我们计算机的网卡设备。该网络适配器便可标识我们的计算机。一个以太网设备的MAC地址类似于00:C4:B5:45:B2:43。而每个适配器都有一个OUI(organizationally unique identifier)标识符来标识制造商,一般可有MAC地址前三个字节用于表示
例如 戴尔 的MAC地址OUI为00-14-22,因此戴尔的网络适配器的MAC地址可能类似:00-14-22-34-B2-C2
IP地址
与硬件无关的用于识别网络设备的地址,会根据IPv4 IPv6而又有不同的语法描述。
就假设IPv4,典型的地址是:10.24.12.4。
通常其用于网络的软件方面,任何连接到互联网的系统都会有一个IP地址,并且如果网络发生变化IP地址也会随之变化,并且在整个互联网中始终唯一(但是如果进行了NAT即网络地址转换)就可能导致多个设备通过一个公网IP进行共享上网从而在内部使用私有IP分配而对外映射为唯一的公网IP
主机名
通过主机名,其获取你的IP地址,将地址与一个特定和易于理解的名称进行绑定(只需要记住域名)
应用层 Apllication Layer
假设我要给Sh1ori发送一个邮件,我们接下来分析一下TCP/IP 层会做什么
记住这些packet包在传输的过程中要包含header头 和一个payload 有效数据
header通常会告诉我们这个包从哪来,要到哪去。数据包在网络中传输,每一层都会在header上添加一些信息,我们称为frame
我们在电子邮件客户端发送邮件时,应用层会对数据进行封装。而应用层通过指定的 端口 与 传输层 通信,然后再通过该端口进行数据发送,我们希望通过应用层的协议SMTP进行发送,该协议会打开到该端口的连接(比如SMTP使用25),然后哦通过端口接收数据后,这些数据被发送到 传输层 进行封装为数据段
传输层 Transport Layer
帮助我们将数据以网络可读的方式进行传输,它将数据分解成多个块并传输,按照正确顺序重新组合在一起,这些快会被称为段 segments,使得网络数据传输更方便容易,接下来讲传输层的概念
- Ports 端口,引出这个概念,我们虽然知道了远程的IP地址,但不足以让我们将数据发送到特定的进程或服务上。像HTTP的服务会使用端口作为通信通道。如过我们需要发送网页的数据,就通过HTTP端口(80)发送。除了形成数据,传输层同时将源地址和目标地址的端口都附加到了数据段上,这样双方都可以知道使用的端口
- UDP 并不可靠,现在也不常用,但确实在一些地方会进行使用,例如在媒体流传输中,即使丢失一些帧也没关系,因为这样可以更快地获取数据。
- TCP 提供可靠的面向连接的数据流,使用端口和主机之间收发数据。应用程序会从主机的一个端口建立到另一个远程主机端口,对此我们掏出了三次握手协议来确保客户端和服务器能够进行一次正常通信连接
- 1 客户端(连接进程)发送SYN segment=1(同步标志位) 给服务器来请求一次连接并随机生成一个初始数据包序列号
seq=x含义:“服务器,我想与你连接,我的seq=x,能否听到我?” - 2 服务器->客户端,回复一个
STN=1和ACK=1的段,随机生成一个初始序列号seq=y,并确认客户端的数据包序列号ack=x+1(下一次从x+1开始)含义:“我可以听到!(此时ack=x+1),我的seq=y,可以与你进行连接,能否听到?” - 3 客户端->服务器,发送一个
ACK=1的段,确认服务器序列号ack=y+1,并且此时序列号为seq=x+1(seq客客户端数据接着上一次开始发送)含义:“我还在!(此时ack=y+1)那么我们开始通信吧!” 或者可以看到表格步骤 发送方 接收方 动作 第一次 客户端 A 服务端 B SYN (同步序号):A 发送一个 SYN 包到 B,并指明自己希望建立连接。A 进入 SYN-SENT状态。第二次 服务端 B 客户端 A SYN-ACK (同步+确认):B 收到 SYN 后,发送 SYN-ACK 包。SYN 表示 B 同意建立连接;ACK 表示确认收到了 A 的 SYN。B 进入 SYN-RECEIVED状态。第三次 客户端 A 服务端 B ACK (确认):A 收到 B 的 SYN-ACK 后,发送一个 ACK 包进行确认。A 进入 ESTABLISHED状态。B 收到 ACK 后,也进入ESTABLISHED状态。
- 1 客户端(连接进程)发送SYN segment=1(同步标志位) 给服务器来请求一次连接并随机生成一个初始数据包序列号
通过三次握手,数据可以有条理的进行交换并实现客户端和服务器的通信,并且消灭掉超时的连接,避免冗余的历史连接(如果只有两次握手就可能导致前一次历史的SYN=1的信号在发送失败后重新连网时再次发送给服务器接受导致识别为错误的失效历史连接)
然后是四次挥手,其为TCP用来安全、可靠地终止连接的机制,由于 TCP 是全双工的(双方可独立发送和接收),关闭连接也必须分两次进行。
| 步骤 | 发送方 | 接收方 | 动作 |
|---|---|---|---|
| 第一次 | 客户端 A | 服务端 B | FIN (终止):A 发送 FIN 包,表示 A 不再发送数据。A 进入 FIN-WAIT-1 状态。 |
| 第二次 | 服务端 B | 客户端 A | ACK (确认):B 收到 FIN 后,发送 ACK 包确认收到。此时 B 仍可向 A 发送数据。A 进入 FIN-WAIT-2 状态;B 进入 CLOSE-WAIT 状态。 |
| 第三次 | 服务端 B | 客户端 A | FIN (终止):B 发送完所有数据后,发送 FIN 包,表示 B 也不再发送数据。B 进入 LAST-ACK 状态。 |
| 第四次 | 客户端 A | 服务端 B | ACK (确认):A 收到 B 的 FIN 后,发送 ACK 包确认。A 进入 TIME-WAIT 状态(等待 2MSL 时间后进入 CLOSED);B 收到 ACK 后立即进入 CLOSED 状态。 |
网络层 NetWork Layer
决定数据包从源到客户端的route,数据包在同一网络中传输;而互联网由许多网络组成,构成互联网的较小的网络被称为子网。所有子网以某种方式相互连接,因此我们可以上网进行网址访问。
网络层中接受传输层的报文段并封装在IP数据包中,将源的IP地址和目标主机的IP地址附加到数据包的header中。最后数据包包含了目的地、来源信息,发送到链路层
链路层 Link Layer
TCP/IP模型的最底层。也是硬件特定的层,我们的数据包再次封装成frame,头部是源MAC地址和目标MAC地址,checksums校验值和分隔符来判定包的尾部
幸运的是在一个网络上,我们的包不必传输很远。首先,链路层将我们源机的MAC地址放到frame头部,现在我们需要知道Sh1ori的MAC地址,嘶怎么知道呢?既然Sh1ori不在互联网上,我们如何找到他——ARP!
ARP(Address Resolution Protocol) 是用来解析查找与IP地址相关联的MAC地址的。ARP在同一网络内使用。如果Sh1ori跟我们不再同一网络上,我们会使用route系统来确定下一个可以接收到数据包的路由器。一旦进入到同一网络了我们就可以使用ARP解析。
当我们处于同一网络中,系统首先使用ARP查找表,表中存储了IP地址与MAC地址对应信息。如果表不存在就使用ARP。系统使用ARP协议向网络发送广播信息,以查找IP地址为xx.xx.x.x的主机。
广播信息是一种特殊信息,会发送给网络上所有主机。而任何拥有所请求查找IP地址的机器便会恢复一个ARP包包含IP地址和MAC地址
我们得到必要数据后,链路层通过网卡将该frame转发。 但是!数据包不是跟我说的一样那么简单传输的,实际上我们没有到达Sh1ori的网络呢!在这个过程中,至少经过两次TCP/IP模型在任何数据送达或接收前。这个数据包经历的过程大概是这样的
- Nan0in给Sh1ori发邮件,数据->传输层
- 传输层中数据封装到TCP/UDP中形成段,附加目标和源的TCP或UDP端口,段发到网络层
- 网络层将数据封装到IP数据包中,附加源IP和目标IP,路由到链路层
- 数据包到达Nan0in硬件中封装成帧,对应IP也封装进去
- Sh1ori通过物理层接收该数据帧并检查数据完整性,解封帧内容,将IP数据包发到网络层
- 网络层读取数据包,查找附加的源IP和目标IP,检查是否与目标IP相同,相同则解封数据包,发送到传输层
- 传输层解封数据段,检查TCP/IP端口,根据端口和应用层建立联系
- 应用层从指定端口的传输层接收数据,然后呈现给Sh1ori
DHCP
DHCP(Dynamic Host Configuration Protocol)动态主机配置协议 为我们的机器分配IP地址、子网掩码以及网关。可以联想一下手机号码和电话运营商的关系
优势很多,网络管理员可以方便的分配IP地址并防止重复,每个物理网络都用对应DHCP服务器,方便主机申请IP地址,在常规家庭中则是路由器。目前来看DHCP获取所有动态主机信息的方式有
- DHCP DISCOVER——client通过广播信息来搜索DHCP服务器,
- DHCP OFFER——DHCP服务器回复信息。包括一个数据包:包含 DHCP 租用时间、子网掩码、IP 地址等信息。client收到后
- DHCP REQUEST ——客户端选择DHCP发出了另一个广播,让DHCP服务器知道它接受哪个提议
- DHCP ACK——服务器发送确认
而DHCP服务器需要静态IP才能有效管理,可以处理DNS和网络数据。DHCP服务器可以有效地管理IP地址和相关信息,确保每台客户端获得唯一的IP和所有正确的网络信息 DHCP协议说明
Subnetting 子网划分
子网划分将网络划分为更小的子网,提高Linux网络性能和安全性。按照IP寻址的方案组织IP地址,防止冲突,高效利用地址范围。用route -n可以查看路由表,而route add -net xxx.xxx.xxx.x/xx gw yyy.yyy.yyy.y可以添加子网,将发送到xxx…网段的ip转发到静态路由网关
Ethernet & arp/rarp
以太网(LAN local-area network) ARP(地址解析协议——将IP地址转换为MAC地址)RARP(反向ARP)
通过这些协议,本地网络通信和地址解析得以实现
什么是DNS?
DNS,即Domain Name System,域名系统,就像互联网上的电话簿,它有以下的工作原理
- 人性化的域名
- 机器可读地址——IPV4地址
- DNS翻译,后台会将域名自动转化为IP地址
Linux系统使用DNS
/etc/resolv.conf来配置DNS解析,使用nslookupdig命令进行查询DNS和排除网络连接问题,在我的arch linux上打开看到是像下面这样的
| |
如果在你的服务器上,nameserver是DNS服务商的IP(可以是你服务器自己的),domain是本地主机的域名,通过设置多个要尝试自动添加的域名后缀,按顺序搜索直到找到有效结果。(search和domain是冲突的,不能同时使用)
你可以用dig命令来干一些有意思的事情

dig -x可以挖掘出更多用惯特定IP的信息IP Routing
IP路由,设计配置路由表和网络路由以便在网络上转发数据包。而内核选择路由以方便将数据包发送到目的地。使用ip命令进行配置。使用ip route show我们可以显示所有内核已知路由来排除故障和管理

这里有一个默认路由,通过网关地址via后的进行跳转。dev wlp0s20f3则是使用的无线网络接口。proto dhcp说明通过DHCP动态获得

| |
通过Ping或者host命令我们可以确保可以访问到网关、互联网上的其他网站
SSH
Secure Shell,想必不需要我们讲了,它提供点对点的安全远程访问、命令执行和通信。我们可以设置基本的ssh配置,也可以通过ssh密钥对进行身份验证管理;例如通过ssh git@111.229.23.145连接上我的服务器。ssh username@server_IP是连接的基础方式
File Transfer
Linux文件传输涉及在网络 系统之间复制或移动文件。命令行上支持使用FTP HTTP SCP NFS等协议。常用命令有scp rsync和wget
shell programing
shell编程,通过脚本自动执行Linux中的管理任务、重复操作和系统监控。btw,我使用zsh。
shell变成非常适合系统自动化
| |
就可以easily print your first “hello world"了
可以试试这个学习 Shell - 免费交互式 Shell 教程