
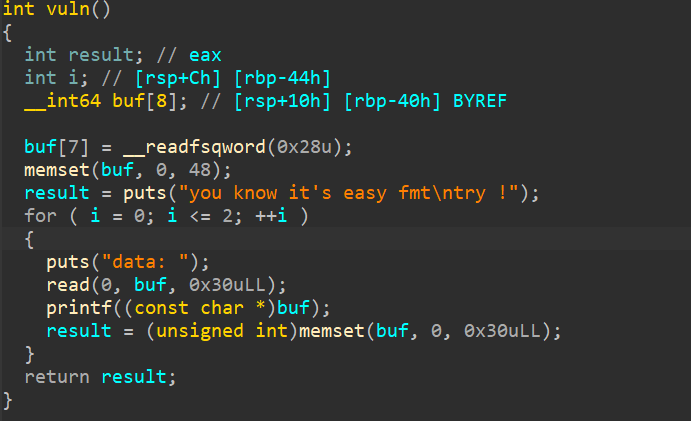
解出总计10题
hgame week1 wp
misc
Hakuya Want A Girl Friend
下载得到一个hky.txt
打开一看有一大堆的十六进制文本,放到010editor中后导出文件,然后放到随波逐流

提取出一个压缩包,刚打开时显示已损坏但是还可以继续查看,那么压缩文件是没问题的
然后我在010editor中疯狂找密码找不出来,还傻乎乎地去锤出题人 后来发现结尾是
0A 1A 0A 0D 47 4E 50 89,反过来就是png文件的头,把压缩包部分删去后反转一下 附上反转脚本:
反转脚本
| |
得到一张png图片,看了看没什么其他信息后应该是改宽高了,放随波逐流
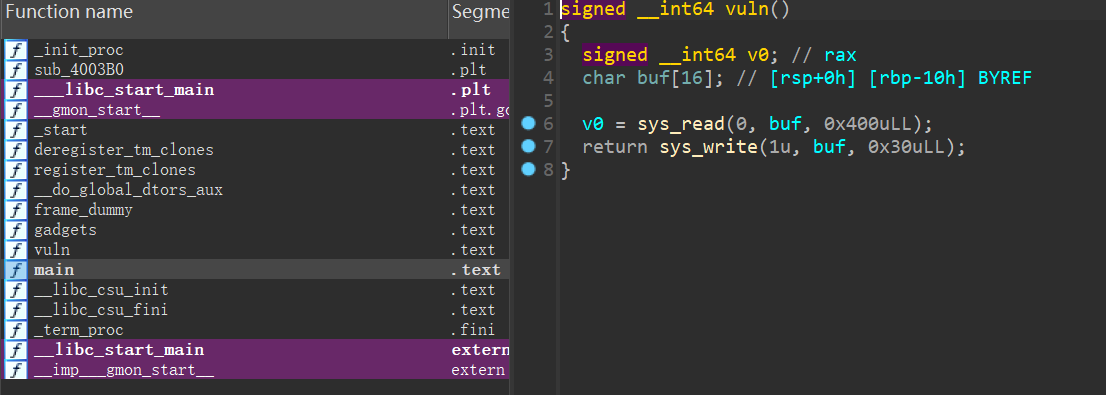
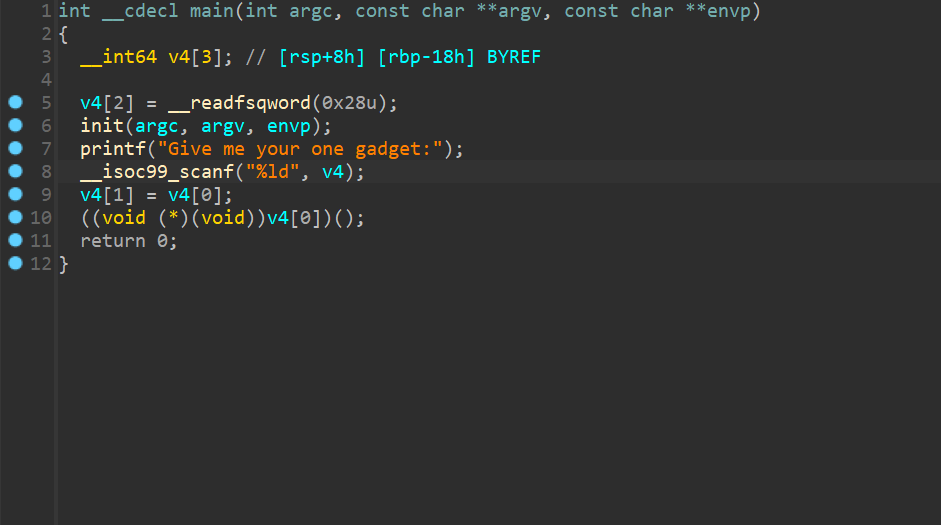
hakuya的QQ号,但是不对,那么应该就是里面的这个密码
解压,得到flag
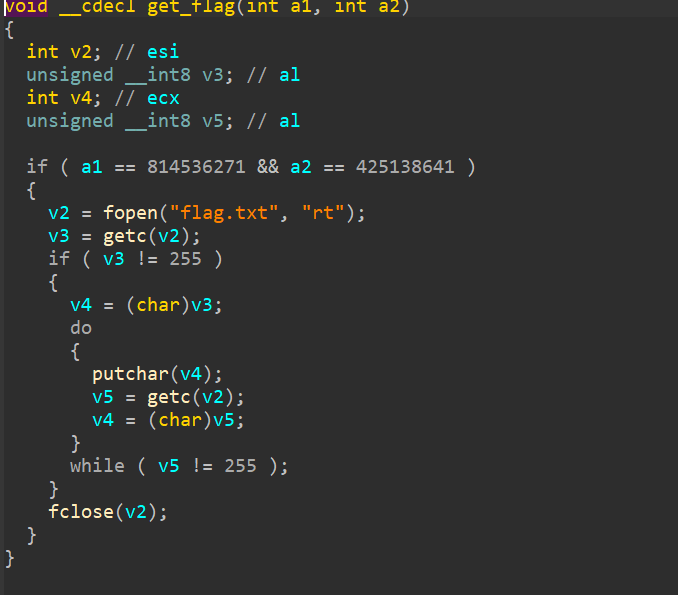
hgame{h4kyu4_w4nt_gir1f3nd_+q_931290928}Level 314 线性走廊中的双生实体
呃呃下载得到一个entity.pt文件,不知道是什么东西,
010editor看一下
发现一大堆pk,放到
随波逐流里解压试试
提取出来一个model?还是不知道是什么东西,上网搜一下
在这篇文章 找到了类似的东西 so——
.pt文件就是PyTorch框架的模型保存格式,其中会保存PyTorch模型的结构和参数,以便后续加载并使用这些模型来推理和训练那么按照题目意思来说的话,我们首先要加载模型
| |
然后我们要给模型输入一组张量,尝试激活得到输出消息,那么张量的值要怎么确定?,考虑到题目中的确保稳定态,我们到调用的__torch__.py中看一看
| |
发现这么一个函数,那么我们就可以确定张量的值了,只要使张量的均值限制在0.31415,同时要注意 输入张量的现实稳定系数(atol)必须≤1e-4 系统才会给我们flag的值
exp
| |
按道理来说应该一次就可以得到了,但是误差控制可能有点小问题,多试了几下出了
| |
flag{s0_th1s_1s_r3al_s3cr3t} 后继:其实题目中周率三分隐玉衡,十方镜界启玄晶诗句的意思就在提醒我们0.314这个参数就是$\Pi$/10
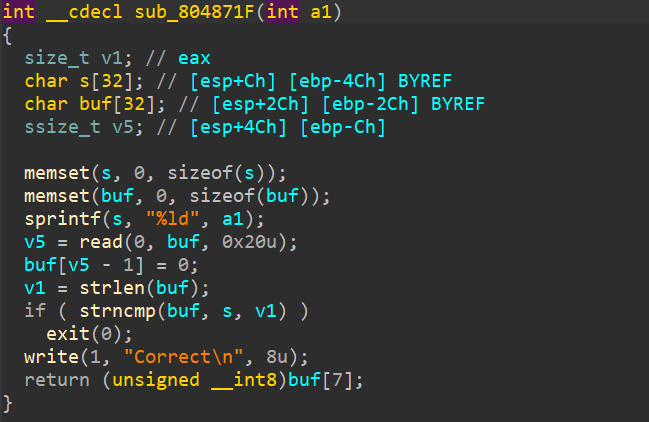
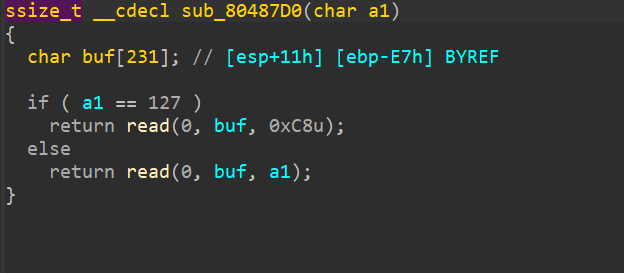
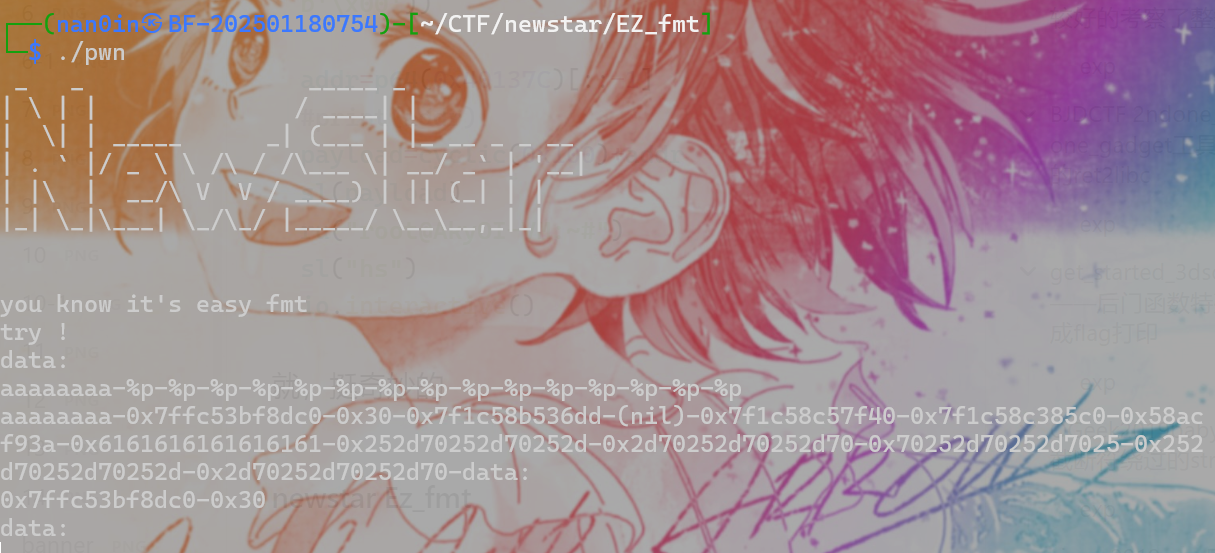
computer cleaner
题目要求有三个:
- 找到攻击者的webshell连接密码
- 对攻击者进行简单溯源
- 排查攻击者目的
先进入虚拟机,简单翻找一下
然后我在这卡了半天,我一直以为本地会有记录或者中间部分就是flag,结果。。
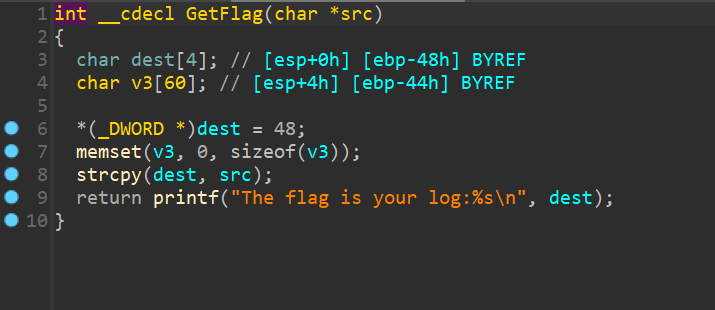
直接访问就有中间的flag了
hgame{y0u_hav3_cleaned_th3_c0mput3r!}
web
Level 24 Pacman
送分题
只有前端,肯定不是玩游戏玩到10000分 失败一次试试
base64解码+2栏栅栏密码,得到hgame{practice_makes_perfet},答案不是这个,提交会显示

有两串base64字符串,上面这串就是
hgame{u_4re_pacman_m4ster}
Level 47 BandBomb
解析
下载得到附件app.js,后端代码中翻找
| |
一个文件上传一个文件重命名函数,没怎么做过web不是很懂,不过可以通过nodejs布置本地,加上const port=3000,本地node app.js运行后可以在本地先测试一下
打开靶机看看
这里可以选择本地文件和上传文件,问了一下ai这题使用的是express框架 (之前杭助学后端的时候学了一点nodejs)
再回去看一下,
/rename并没有对newName进行过滤,所以是不是可以包含路径?
并且multer中fileFilter并不会过滤文件类型,上传 可执行脚本的话就会直接解析!!
那么就有尝试的思路了- 在文件上传的时候,是否可以上传一个带有恶意代码的js文件,并让服务器执行?例如,如果上传的文件被当作Node.js模块加载,但需要特定的条件。或者,通过模板注入,因为应用使用ejs模板引擎。如果攻击者可以控制模板的内容,那么可能进行RCE。
- 由于文件会渲染mortis模板,所以我们覆盖为
mortis.ejs并插入恶意代码执行 - 渲染后访问首页,触发模板渲染并执行恶意代码 OK思路完全畅通,开始动手
解题
在本地创建一个mortis.ejs文件,由于不知道flag会在哪,于是
| |
先这样尝试一下,然后上传文件之后在apifox中发送请求
目录似乎不对,调整一下
ok成功,但是没有flag,所以应该是藏在了其他地方,或许是环境变量?(pwn题也有类似的题目过) 修改一下
| |

找到flag
hgame{ave_mUjIC4_h4S-bROKEN-uP-but-we-hAv3-UMlTakI12}
crypto
sieve
解析
两种不同口径的筛子才能筛干净 题目主要部分
| |
打开sage文件可以看到使用了euler_phi(k)和trick(k),一个是欧拉函数,一个是递归函数,
e^2//6=715,849,728
n=7e8
考虑两种筛法可能就是要对大数的筛选进行优化
这里要考虑如何优化
- 使用可以同时计算欧拉函数和素数个数的筛法,搜索得到例如线性筛法就可以在o(n)内计算出结果n=7e8时应该不会再很长时间后才能跑出来
- 分段筛法
- 寻找能将sum_phi和prime_count结合的高效计算方式
两种不同口径的筛子: >1. 线性筛法:高效计算每个数的欧拉函数 phi(i),同时标记素数。 >2. 埃拉托斯特尼筛法:用于标记素数,但是不计算欧拉函数。 k - (k-1)! % k - 1 判断素数 trick(k)实际上就是
\[ \text{trick}(k) = \sum_{i=1}^{k} \varphi(i) + \pi(k) \]
我一开始的解法
| |
遗憾的是在跑了半个小时之后宣告失败了,实际上跑出来是一堆乱码,compute_trick函数计算错误了,线性筛法存储整个数组效率野果低 然后思考了一下,想起之前ACM课教的位压缩和优化,顺手问了一下deepseek,优化了一下脚本。 思路:
- 解析题目中的“两种不同孔径的筛子”指的是线性筛法和埃拉托斯特尼筛法,或者欧拉筛法和另一种筛法,用于计算欧拉函数和素数个数。
- 根据trick函数的逻辑,正确计算trick(k)=sum_phi + prime_count,使用高效的筛法实现。
- 优化compute_trick函数,使其在Python中能够处理k=7e8,可能使用numpy或其他优化库。
- 生成正确的p和q,解密得到flag。 考虑到时间要求,我们不可能跑所有的trick(k),并计算p=nextprime(trick(k)«128)去解密。
exp
| |
hgame{sieve_is_n0t_that_HArd}
re
COMPRESS_DOT_NEW
下载解压得到两个文件,enc_txt一大堆数据文本看不懂
还有一个compress.nu文件,也不知道是什么,搜索一下找到nushell这样一个终端
- NUSHELL解决 compress.nu脚本定义了一系列函数,用于构建Huffman树、生成编码表、以及进行数据压缩。
into b:将输入转换为字节数组。
gss 和 gw:用于从树节点中提取字符和权重。
oi:插入节点到有序列表中。
h:构建Huffman树。
gc:生成字符到编码的映射表。
sk:简化树结构。
bf:计算字符频率。
enc:使用编码表对输入数据进行编码。 下载完之后
| |
就可以了(一开始nu命令用不了就做不出来)
2.脚本解决
enc.txt中的前半部分是一个JSON树结构,后半部分是二进制数据
先把前半部分提取出来
例如
| |
两个根a和b 那么各个路径为:
字符125的路径是 a -> a -> a,编码为 000。
字符119的路径是 a -> a -> b,编码为 001。
字符123的路径是 a -> b,编码为 01。
字符104的路径是 b,编码为 1。
问了下AI如何将这个数和二进制数据对应起来 答案是生成和遍历一个Huffman树(死去的算法记忆开始攻击我) 找了半天找到了一个可以改了改可的解析脚本
| |
hgame{Nu-Shell-scr1pts-ar3-1nt3r3st1ng-t0-wr1te-&-use!}
turtle
解析
下载得到附件,
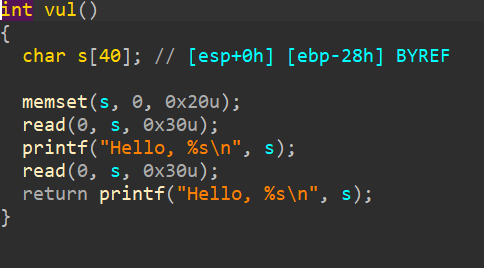
exeinfo看有upx魔改头

010editor看一下,魔改upx头了而且改了很多,所以学了一下用x64dbg手动脱壳
x64dbg打开,f9继续到程序开始处
这里可以看到许多寄存器进行入栈,那么在pop的时候会一并执行,而出栈顺序是反过来的,所以我们ctrl+f搜索pop rbp,找到真正进入点

f7单步进入,然后scylla手动脱壳后dump后

可以正常IDA打开了

分析以后 上面要注意一点v7和v8数组其实是用于连续存储的数据,改为v7[7]字节数组应该为:0xCD, 0x8F, 0x25, 0x3D, 0xE1, 0x51, 0x4A,对应v7[0]-v7[7],后面进行了RC4加密,密钥是yekyek
最后根据加密部分逆向写解密脚本即可
exp
| |
hgame{Y0u’r3_re4l1y_g3t_0Ut_of_th3_upX!}
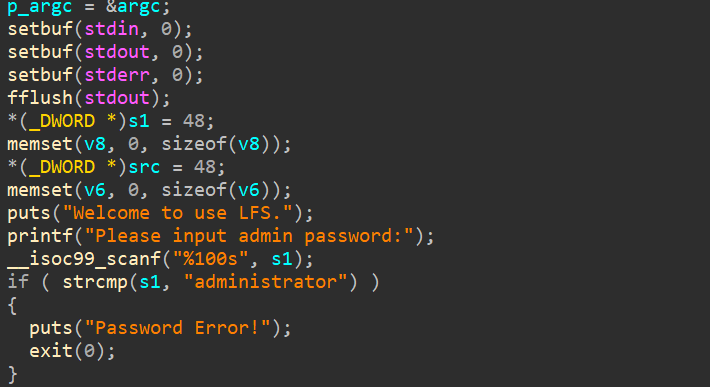
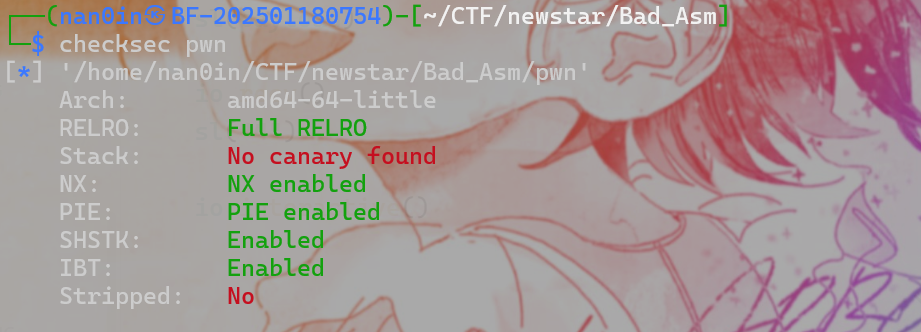
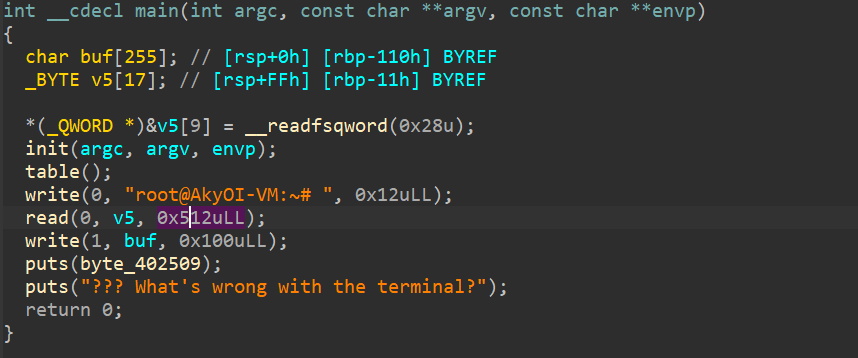
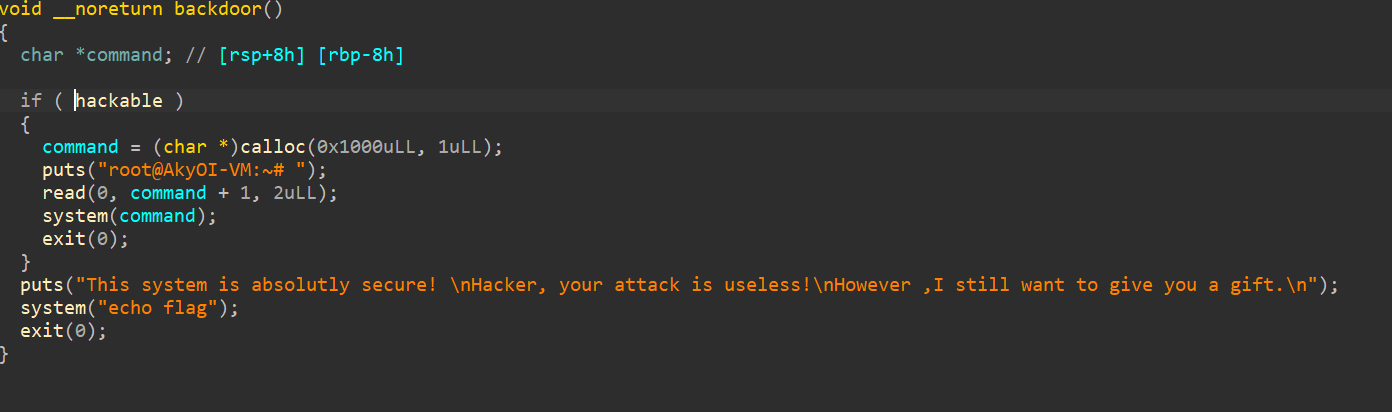
pwn
见博客中Hgame2025其他文章