
堆介绍
CTF PWN中的堆不是我们所了解的数据结构,而是一块动态分配的空间
不同于加载进内存就会出现的栈,堆是由malloc等分配函数分配后才会出现的,并且 从低地址向高地址生长,以下所讲的都是linux下的堆分配知识
对堆的操作由堆管理器(ptmalloc2)实现,之所以不是操作系统内核,是因为每一次程序申请或释放堆时都需要系统调用,频繁进行堆操作会严重影响性能

这就是一个基础堆的结构
- pre size字段只在前面一个堆块空闲会有指向,若前一个堆块在使用则其为0
- size用于指示当前堆块大小,最后三位为3个flag值
NON_MAIN_ARENA chunk是否位于主线程 IS_MAPPED 当前chunk是否由mmap分配 PREV_INUSE 前一个chunk是否被分配,被分配则为1
综上,pre size和size都可用于判断前一个堆块是否释放,malloc函数分配到的内存的返回值指针指向user data 而在chunks有前后连接的时候会变成如下

举例
malloc(8)
在64位中实际上分配到0x21的大小
16+8+8+1
第一个16字节是系统分配最小内存,即如果我们申请内存比其还小就自动申请这么大的内存,即使malloc(0)也会分配(32位是8字节)
第二个8字节为presize大小
第三个8字节为size大小
最后1字节为prev_inuse
而调用malloc函数最后给我们返回一个指向user data的指针
指针表示和链表
IDA中一般表示为*(addr+8),取到addr+8偏移位置存储的值,汇编中一般可以看到mov rax,[地址+偏移]
—->链表
堆题常有一个菜单系统,用链表相连后我们便可以常看note大小属性等来调整堆空间
实例

| |
132kb的大小远大于10字节,这就是main arena
即内核批发给ptmalloc2的货物大小,之后程序如果要申请小内存直接在这之中取即可,我们可以查看一下堆空间

top chunk
堆中第一个堆块,程序以后分配到的内存放到他后面,系统中free chunk不足用其补充chunk
Bins
free()函数和bins分配紧密关联,free后堆块user data被清空,然后堆块指针存储到main_arena中,或者说 ——fast bin
Fast bin
- 概念:为了快速重新分配回内存的结构,我们分配一块小的内存的时候,会检测fast bin中是否存有小chunk,若存在则从fast bin移除然后返回
- fast bin个数为10
- fast bin用单链表来维护一系列释放的堆块,实现 快速的小内存分配和释放由释放晚的堆块指向释放早的堆块且不会对free chunk合并(0x20Bytes-0x80Bytes)

看图可知后进先出(LIFO),先使用第二次的堆块,移除后根据fd所指的前一个堆块(bk指向后一个堆块) main_arena指向fastbin的头部,用于 更新指向下面这个堆块若chunk为末尾块,fd=NULL,表示列表的末尾。
搜索的过程为tcachebin->fastbin->unsortedbin->top chunk
free操作:主要分为两步:先通过chunksize函数根据传入的地址指针获取该指针对应的chunk的大小;然后根据这个chunk大 小获取该chunk所属的fast bin,然后再将此chunk添加到该fast bin的链尾即可。整个操作都是在int freel函数中完成.
small bin
- 概念:small bin空间大于fast bin(小于0x400)
- 不同于fast bin,其为双向链表循环链表结构,最多62个(每个bin会存储固定大小的chunk,同时步长在8-16字节。头部同样位于main_arena,采用先进先出(FIFO)进行操作
free操作:释放时会检查相邻 chunk 是否空闲,若空闲则合并两个small bins,加入到unsorted bin

Unsorted bin
- 概念:unsorted bin 会对堆中碎片chunk合并来减少堆中的残渣(前提是系统没有将这些chunk添加到对应的bins中,chunk不在fastbin范围、或者tcache存在的情况下(tcache已满且块超出tcache大小范围)
- 只存在一个,它由双向循环链表对chunk连接(因为是拼接的chunk嘛)用fd bk指针进行前后的chunk的指向。任何大小的chunk都可以进入,以FIFO遍历
- 作用:通过”glibc malloc“有第二次机会重新利用最近刚释放的chunk(第一次在fastbin机制中),由此加快内存分配和操作
Large bin
- 概念:大于0x400的堆块会分配到Large bin中,,large bin在保存固定size的同时可以保存一系列的sizes(比如0x400 to 0x430 sized chunks are linked into the same large bin)
- 存在63个(NLARGE_BINS = 63),每个bin会存储一个范围内的Bin;双向循环链表,会按照大小进行排序,相同时则最先释放靠前
- 其特殊的地方还添加了(fd_nextsize 和 bk_nextsize),它们仅存在于每个 largebin 的第一个元素中。而
nextsize的指针会构成另一个双向循环链表;此外,malloc 仅当块是 largebin 中的最后一个块时,才会分配带有指针(跳过列表指针)的块nextsize,以避免更改多个指针。free类似small bin

tcache bin
- 概念:即
Thread Local CacheGlibc2.26以及之后,glibc引入tcache机制,使得多线程下堆分配可以有更高的效率,tcache有着类似fast bin的单链表结构且作用也与fast bin相似,不会被合并,优先分配(但数量比fast bin多且线程更为安全) 其效果也类似,释放的chunk会优先考虑放入TCACHE_MAX_BINS的限制使得0x400以上chunk不会放入
每条链子上的mp_.tcache_count限制最多的chunk(默认7)
同时tcache_entry *e=(tcache_entry *)chunk2mem(chunk);的chunk2mem宏i使得tcache链表串起了对应chunk的userdata位置
- 共有64个固定大小tcache bin,且为线程专有
需要注意的是,当chunk从fast-/small bins 分配的时候,malloc会将残留的free chunk塞入到线程进行相应的tcachebin直到填满;对unsorted bin来说也是相似的,任何相似的chunk 符合size要求的都会被放入tcache bin,如果满了就寻找其他符合需求的chunk in unsorted bin,我们也就分配到了这个chunk;而如果我们扫描完了unsorted bin有>=1的chunk(s)进入了tcache,则从tcache分配

Bins的完整工作流程
分配内存(malloc):
- 检查 tcache → fast bins → small bins → unsorted bin → large bins → top chunk → 系统调用新的。
释放内存(free):
若为 tcache 大小,插入 tcache。
否则插入 fast bins(不合并)或 unsorted bin(尝试合并)。
看how2heap例题进行demo测试
Unlink
在分配/释放的过程中,chunks 或许会被从存储的bin中unlink(即与存储链表失去了连接而成为迷失内存)——这些unlinked chunk就会被称为victim
fast or tcache bin (LIFO 单链表)
- 在fast/tcache bin中,unlink是很简单的,因为他们为LIFO结构(Last in First Out)
我们原本是 main arena->Afd->Bfd-> Cfd->NULL ,将A fd复制到链表头部,就跳过A,A is unlinked
small or Unsorted bin or large bin(双向链表)
- 节点通过
fd(指向下一个)和bk(指向上一个)链接。
因此我们部分解除链接:
- 通过 victim 的
bk找到前一个块(prev)和后一个块。 - 将victim 的后一个chunk bk指向前一个chunk
- 将prev chunk的fd指向后一个块
例如
main_arena <-> A <-> B <-> C,要移除B时我们就改A fd和C bk断链 结果上来看我们使了一个巧,通过修改相邻指针B is unlinked
我们不难发现,victim的fd和bk都不变化,而我们就可以利用这点泄漏
- libc 地址
- P 位于双向链表头部,bk 泄漏
- P 位于双向链表尾部,fd 泄漏
- 双向链表只包含一个空闲 chunk 时,P 位于双向链表中,fd 和 bk 均可以泄漏
- 泄漏堆地址,双向链表包含多个空闲 chunk
- P 位于双向链表头部,fd 泄漏
- P 位于双向链表中,fd 和 bk 均可以泄漏
- P 位于双向链表尾部,bk 泄漏
Remaindering
remainder简单来说就是将一个块进行拆分为两部分:请求大小的块和剩余部分。剩余部分便会因此进入到unsorted bin。剩余操作可以发生在三个阶段:
- 从large bin分配时
- binmap搜索时
- 从unsorted bin扫描到
last remainder,即上次分割的剩余部分: 1. 若last remainder且大小>=请求大小+MINSIZE - 分配给用户 - 剩余部分成为新的last remainder` 2. 若不匹配就继续搜索
Exhausting
如在unsorted bin请求一个大小为N的块,但只找到了N+0x10大小的块。所以0x10的大小是没有用的,但是malloc还是会消耗掉这N+0X10的内存大小来分配N
Consolidation
合并就是将堆上至少两个空闲块合并为一个更大的空闲块,以避免碎片化。
同时与顶部块相邻的块的合并也值得注意。
malloc hooks
一系列的特殊hooks会为house of IO以及其他利用技术提供非常重要的帮助,下面为一系列典例
由于使用上的危险,下面的举例已在GLIBC >= 2.34 中删除。
__malloc_hook/__free_hook/__realloc_hook:位于GLIBC 的 writable 段(如libc.so的.data或.bss
作用:默认设置为NULL,在调用GLIBC时默认实现,若非NULL则会调用hook指向的函数——比如覆盖hook执行one_gadget或shellcode,使得调用malloc/free 时执行任意代码
例如*(__malloc_hook)=(void*)system;malloc("/bin/sh");拿到shell__after_morecore_hook:
作用:当sbrk()请求更多内存后调用。在堆扩展时我们可以劫持到堆扩展时的回调__malloc_initialize_hook:
作用:malloc首次初始化时调用(仅一次)。可以在首次调用malloc前触发(条件较为苛刻)__memalign_hook:
作用:When set andaligned_alloc(),memalign(),posix_memalign(),orvalloc()被调用时,这些所指函数的指针地址会存储在hook并被调用__dl_open_hook:
作用:当GLIBC中触发打印回溯的错误信息的时候——典例为backtrace_and_maps()会调用到这个hook打印stderr追踪。 结构:1 2 3 4struct dl_open_hook { void *(*dlopen_mode)(const char *, int); void *(*dlsym)(void *, const char *); };
举例:abort()触发了__backtrace()->init()->__libc_dlopen()的链子我们有以下思路
- 覆盖
_dl_open_hook指向攻击者控制的内存。 - 伪造
dlopen_mode和dlsym指针(如指向system)。 - 触发
abort()或内存错误时执行任意函数。
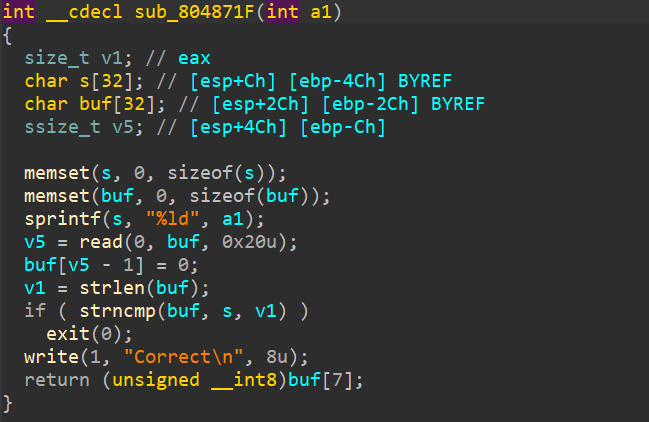
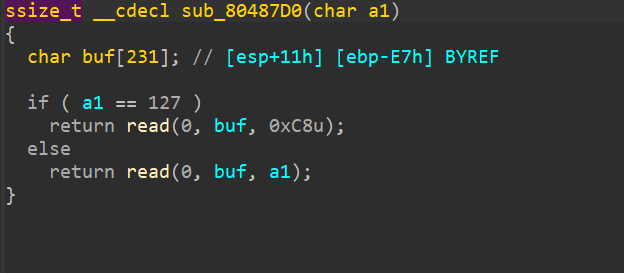
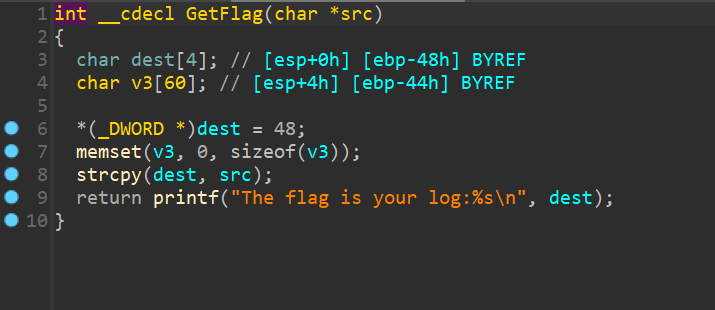
堆溢出
所谓堆溢出就是向某个堆块中写入的字节数超过了堆块本身可使用的字节数(之所以是可使用而不是用户申请的字节数,是因为堆管理器会对用户所申请的字节数调整,实际总是更大的),因而导致了数据溢出,并覆盖到物理相邻的高地址的下一个堆块。
堆溢出前提
- 程序向堆上写入数据
- 可以操控写入数据大小
问题是堆上没有返回地址等可以操控的数据,所以堆溢出 如何getshell?
- 覆盖与其相邻(物理上)的下一个chunk
- 利用堆的机制来任意地址写,或控制堆块内容来控制程序流