一、树状数组 (Binary Indexed Tree)
树状数组是一种支持 单点修改 和 区间查询 的,代码量小的数据结构。
定义每一列的顶端节点为树状数组元素,一般不需要再记录原始数据。
结构特点
1
2
3
4
5
6
7
8
| c[1]=a[1] (001)
c[2]=a[1]+a[2] (010)
c[3]=a[3] (011)
c[4]=a[1]+a[2]+a[3]+a[4] (100)
c[5]=a[5] (101)
c[6]=a[5]+a[6] (110)
c[7]=a[7] (111)
c[8]=a[1]+...+a[8] (1000)
|
c[i] 相当于前 n 个数据的和,而这个 n 来自于 i 的二进制中的最后一个 1 代表的值。树状数组之所以求前缀和快,是因为其将前缀和拆成了 $log,n$ 段区间进行求和。
lowbit 函数
1
2
3
| int lowbit(int x) {
return x & -x;
}
|
将二进制位全部取反,再加 1 就是 -x 的二进制编码(如 6 -> 110,-6 -> 010)。两边相与就可以取出低位的 1 以及后面的 0。
另一种等价写法:
1
2
3
| int lowbit(int x) {
return x - (x & (x - 1));
}
|
x & (x-1) 去掉二进制中最后一个 1,再用 x 减掉即求得最后一个 1 代表的数。
树状数组构建及核心函数
tree[i] 的关键:每一个节点 i 都存储了一段区间的总和,区间长度为 lowbit(i)。
tree[i] 存的是原数组从 i - lowbit(i) + 1 到 i 这几个元素的和- 如
tree[6],lowbit(6) = 2,存了原数组 5 和 6 两个元素
add 函数——由于 lowbit 包含当前组,可以一直溯源到顶部数组:
1
2
3
4
5
6
| void Add(int tree[], int i, int j, int n) {
while (i <= n) {
tree[i] += j;
i += lowbit(i);
}
}
|
之所以 +lowbit(i),是在保证包含当前 tree[i] 的情况下扩大范围。
query 函数——查询前 i 长度的前缀和:
1
2
3
4
5
6
7
8
| int Query(int tree[], int i) {
int sum = 0;
while (i > 0) {
sum += tree[i];
i -= lowbit(i);
}
return sum;
}
|
应用:冒泡排序与逆序对
冒泡排序的交换次数取决于逆序对数量。用树状数组存储数字 i 到 j 的区间前缀和,数字 x 出现便置为 1 并更新数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| #include <stdio.h>
#include <string.h>
int n;
int tree[100005];
int lowbit(int x) { return x & (-x); }
void add(int i, int val) { // 标记数字 i 出现了 1 次
while (i <= n) {
tree[i] += val;
i += lowbit(i);
}
}
int query(int i) { // 查询 [1, i] 出现了多少个数字
int sum = 0;
while (i > 0) {
sum += tree[i];
i -= lowbit(i);
}
return sum;
}
int main() {
while (scanf("%d", &n) != EOF) {
memset(tree, 0, sizeof(tree));
long long swaps = 0;
for (int i = 0; i < n; i++) {
int x;
scanf("%d", &x);
swaps += i - query(x); // 比 x 大的数有多少个
add(x, 1);
}
printf("%lld\n", swaps);
}
return 0;
}
|
与差分数组的关系
如果每次对区间 [a, b] 进行了统一修改,那么区间内部的差分为 0。但:
- a 处相对于上一个数差分 +1
- b+1 处相对于上一个数差分 -1
而差分数组的前缀和,就是精准到点的具体值。
二、线段树 (Segment Tree)
树状数组可以做的线段树都可以做到,但是代码上会复杂一些。
每一次操作都是对某一段区间的修改或查询。
线段树原理
假设有编号 1-n 的 n 个点,每个点都存了一些信息,用 [L, R] 表示下标从 L 到 R 的区间信息。
将 [1, n] 分解成若干特定子区间(数量不超过 4n),然后将每个区间 [L, R] 都分解成少量特定子区间,通过对这些少量子区间的修改或统计,来实现快速对 [L, R] 的修改或统计。
线段树是一棵平衡二叉树,但不是完全二叉树。
性质
- 每个区间长度是区间整数的个数
- 叶子节点长度为 1,不可再分
- 若单个节点对应区间
[a, b],则其子区间对应节点为 [a, (a+b)/2] 和 [(a+b)/2+1, b]
- 线段树高度为 $\lceil \log_2(b-a+1) \rceil + 1$
- 线段树把区间上任意一条线段都分成不超过 $2\log N$ 条
注意
例如上图中要查询 5-10,只需要 5-7 + 8-10 两条合起来即可。即每一层最多只需选择两个节点组合出父节点,而高度为 $\log N$。
线段树定义
1
2
3
4
5
6
7
8
| #define maxn 100007 // 元素总个数
int A[maxn]; // 原始数组,不一定要用
struct SegTreeNode {
int val; // 节点值
// int lazy; // 懒惰标记(延迟更新标记)
// 根据题目需要增加元素
} SegTree[maxn << 2]; // 定义线段树
|
线段树构造
1
2
3
4
5
6
7
8
9
10
| void build(int l, int r, int rt) { // 根为 rt,区间为 [l, r]
if (l == r) {
SegTree[rt].val = A[l];
return;
}
int m = (l + r) / 2;
build(l, m, rt * 2); // 递归构造左右子树
build(m + 1, r, rt * 2 + 1);
PushUp(rt); // 回溯,向上更新
}
|
rt 可以理解为实际存储的下标。递归到最后将值给回父节点,实际上只需做求子树和:
1
2
3
| void PushUp(int rt) {
SegTree[rt].val = SegTree[rt << 1].val + SegTree[rt << 1 | 1].val;
}
|
单点更新(假设 A[L] += C)
1
2
3
4
5
6
7
8
9
10
11
| // l, r 表示当前节点区间,rt 表示当前线段树的根节点编号
void Update(int L, int C, int l, int r, int rt) {
if (l == r) {
SegTree[rt].val += C;
return;
}
int m = (l + r) >> 1;
if (L <= m) Update(L, C, l, m, rt << 1);
else Update(L, C, m + 1, r, rt << 1 | 1);
PushUp(rt);
}
|
区间查询(询问 A[L..R] 的和)
1
2
3
4
5
6
7
8
9
10
11
| // [L,R] 是操作区间,[l,r] 是当前区间,rt 是当前节点编号
int Query(int L, int R, int l, int r, int rt) {
if (L <= l && r <= R)
return SegTree[rt].val;
if (L > r || R < l) return 0;
int m = (l + r) >> 1;
int ANS = 0;
if (L <= m) ANS += Query(L, R, l, m, rt << 1);
if (R > m) ANS += Query(L, R, m + 1, r, rt << 1 | 1);
return ANS;
}
|
区间更新引入 — 延迟标记 (Lazy Tag)
由于更新某个区间内所有叶子节点的值会影响其相应的非叶子节点,回溯更新的非叶子节点也会有很多,时间复杂度会大幅上升。
为此,引入线段树中的延迟标记(Lazy Tag)概念。
提示
延迟更新的意义:
- 多次更新、一次下推
- 无需要,不下推 —— 用不到孩子就不用更新孩子
假设操作:把区间 [1, 100000] 全部改成值 3。
如果逐个点更新:更新 100000 次 ❌(会超时)
但你想表达的只是:这一整段都是 3。所以不需要真改每个点,标记一下即可。
什么时候才"下发" lazy?
- 要访问子节点时
- 要查询子节点时
完整流程示例
初始:[1, 5] = 1 1 1 1 1
操作 1:更新 [1, 5] = 3
根节点直接 val = 5 * 3 = 15,lazy = 3,没有递归下去。
操作 2:更新 [2, 3] = 2
现在问题来了:节点有 lazy = 3,但你只想改 [2, 3],必须先 PushDown!
1
2
3
| 把 [1,5] 的 lazy=3 下发:
左:[1,3] = 3 3 3
右:[4,5] = 3 3
|
然后再继续更新 [2, 3]。
线段树定义(有 lazy 标记)
lazy = “这个区间还没真正下发的操作”
1
2
3
4
5
6
7
| #define maxn 100007
int A[maxn];
struct SegTreeNode {
int val;
int lazy;
} SegTree[maxn << 2];
|
线段树构造(有 lazy 标记)
1
2
3
4
5
6
7
8
9
10
11
| void build(int l, int r, int rt) {
SegTree[rt].lazy = 0;
if (l == r) {
SegTree[rt].val = A[l];
return;
}
int m = (l + r) / 2;
build(l, m, rt * 2);
build(m + 1, r, rt * 2 + 1);
PushUp(rt);
}
|
区间更新(以 A[L,R] += C 为例)
1
2
3
4
5
6
7
8
9
10
11
12
| void Update(int L, int R, int C, int l, int r, int rt) {
if (L <= l && r <= R) {
SegTree[rt].val += C * (r - l + 1); // 更新数字和
SegTree[rt].lazy += C; // 累加(或用赋值,看需求)
return;
}
int m = (l + r) >> 1;
PushDown(rt, m - l + 1, r - m); // 下推后才准确更新子节点
if (L <= m) Update(L, R, C, l, m, rt << 1);
if (R > m) Update(L, R, C, m + 1, r, rt << 1 | 1);
PushUp(rt);
}
|
PushDown 处理子节点:
1
2
3
4
5
6
7
8
9
10
| // ln, rn 分别表示左右子树的区间大小
void PushDown(int rt, int ln, int rn) {
if (SegTree[rt].lazy) {
SegTree[rt << 1].lazy = SegTree[rt].lazy;
SegTree[rt << 1 | 1].lazy = SegTree[rt].lazy;
SegTree[rt << 1].val = SegTree[rt].lazy * ln;
SegTree[rt << 1 | 1].val = SegTree[rt].lazy * rn;
SegTree[rt].lazy = 0; // 清除本节点标记
}
}
|
区间更新后的区间查询
1
2
3
4
5
6
7
8
| int Query(int L, int R, int l, int r, int rt) {
if (L <= l && r <= R)
return SegTree[rt].val;
if (L > r || R < l) return 0;
int m = (l + r) >> 1;
PushDown(rt, m - l + 1, r - m); // 下推让子节点数据正确
return Query(L, R, l, m, rt << 1) + Query(L, R, m + 1, r, rt << 1 | 1);
}
|
线段树的应用范围
线段树统计的东西必须符合区间"加法"——否则无法通过二分子区间得到 [L, R] 的统计结果。
符合区间加法的例子:
- 区间数字之和 = 左区间和 + 右区间和
- 区间最大值 = max(左区间最大, 右区间最大)
- 区间最大公因数 (GCD) = gcd(左区间 GCD, 右区间 GCD)
线段树非常重要!一个问题只要能转化成对一些连续点的修改和统计问题,基本就可以用线段树解决。
三、二分专题
二分查找
单调不下降数组 a[1..n],问 x 是否在其中。
- 假设已知答案位于
[l, r] - 若
l > r,说明 x 不在其中 - 否则取
mid = (l + r) / 2,比较 x 与 a[mid]:x == a[mid] 则找到x < a[mid] 则区间缩小为 [l, mid-1]x > a[mid] 则区间缩小为 [mid+1, r]
高级二分:序列划分
给定 n 个正整数 a[1..n],将这个序列从左到右划分成 m 段,每段至少一个数。需要让数字之和最大的那段尽可能小。
1 <= m <= n <= 1000001 <= a[i] <= 10^9
单调性:最大的和不可能比所有和大,不可能比最大的数小 → 答案区间 [max(a[1..n]), sum(a[1..n])]
思路
设 f(x) 表示每一段数字之和不超过 x 时,至少划分成多少段。贪心计算:从左往右考虑每个数,能不切就不切。
f(x) >= f(x+1) 显然是单调函数(x 增大,划分更宽松)。
1
2
3
4
5
6
7
8
9
10
11
12
| int f(long long x) {
long long sum = 0; // 当前段数字之和
int cnt = 1; // 最少切出段数
for (int i = 1; i <= n; i++) {
if (a[i] > x) return -1;
if (sum + a[i] <= x)
sum += a[i];
else
sum = a[i], cnt++; // 开启新段
}
return cnt;
}
|
二分求解:
1
2
3
4
5
6
7
8
9
10
11
12
| long long solve(long long mx, long long sum) {
long long l = mx, r = sum, ans = r;
while (l <= r) {
long long mid = (l + r) / 2;
int tmp = f(mid);
if (tmp <= m)
ans = mid, r = mid - 1;
else
l = mid + 1;
}
return ans;
}
|
例2:Ice Cream Tower
给定 n 个正整数 a[1..n] 和正整数 k。塔满足 b[1]*2 <= b[2],b[2]*2 <= b[3],以此类推。要从中选择数字叠出尽量多的高度为 k 的塔。
2 <= n <= 10000,2 <= k <= 30,1 <= a[i] <= 10^9
二分:最多 mid 座塔,mid ∈ [0, n/k]
贪心:
- 排序 a
- 取出最小
mid 个数作为每座塔第一层 - 对于 2~k 层,对每座塔在剩余数中找第一个
>= need(上一层 ×2)的数 - 若找不到足够数,
mid 不可行
二分边界:下界 lo = 0,上界 hi = n/k。
例3:第 k 小的数
给定 n 个正整数 a[1..n] 和 m 个正整数 b[1..m],在 n*m 个 a[i] + b[j] 中找到第 k 小的数。
1 <= n, m <= 100000,1 <= k <= n*m
二分答案:答案区间在最小和与最大和之间。f(x) 表示有多少对 (i, j) 满足 a[i] + b[j] <= x,f(x) <= f(x+1) 为单调函数。找最小的 x 满足 f(x) >= k。
提示
给定 x 如何统计有多少对满足 a[i] + b[j] <= x?使用双指针。
1
2
3
4
5
6
7
8
9
| long long f(int x) {
long long cnt = 0;
int j = m;
for (int i = 1; i <= n; i++) {
while (j && a[i] + b[j] > x) j--;
cnt += j;
}
return cnt;
}
|
四、KMP 字符串匹配
引入
暴力枚举字符串匹配:母串 A(长度为 n),模式串 B(长度为 m),复杂度 $O(nm)$。当匹配 99% 后最后一个字符失败时,效率极低。
KMP 基本思想
提示
- i 不会减小
- 永远比较
i+1 和 j+1 - 利用"已匹配部分"的对称性
- 用指针 i 表示 A 串,用指针 j 表示 B 串
A[i-j+1..i] = B[1..j] 并且 j = m 时 B 是 A 的子串
当 A[i+1] = B[j+1] 时,i 和 j 各加一。
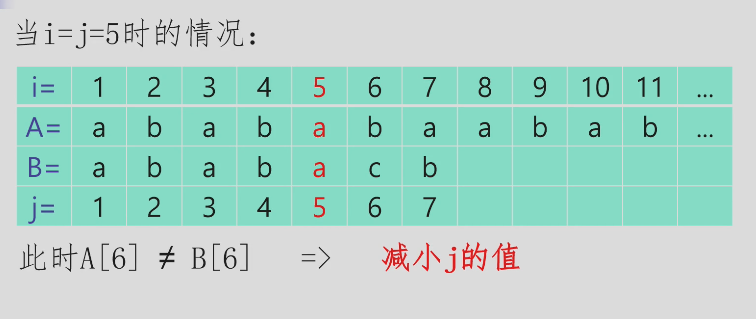
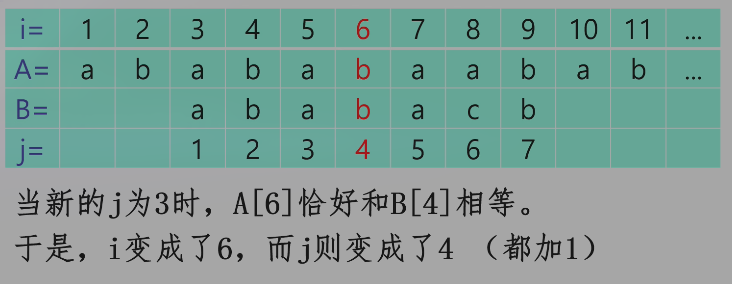
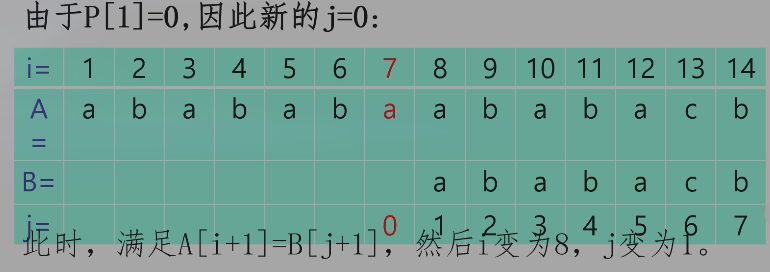
当 A[i+1] != B[j+1] 时,KMP 策略为调整 j 的位置(减小 j),使得 A[i-j+1..i] 与 B[1..j] 保持匹配,且新的 B[j+1] 恰好与 A[i+1] 匹配。
这个回退过程其实是找最长相等真前后缀(既是前缀又是后缀,但不能是它自己)。
代码实现
1
2
3
4
5
6
7
8
9
10
11
| // 字符串 A 和 B 都从下标 1 开始存储
int ans = 0, j = 0;
for (int i = 0; i < n; i++) {
while (j > 0 && B[j + 1] != A[i + 1])
j = P[j]; // 不能继续匹配且 j 还没到 0,右拉找最大前后缀匹配
if (B[j + 1] == A[i + 1]) j++;
if (j == m) {
printf("%d\n", i - m + 1); // 输出子串在母串中的位置
j = P[j]; // 继续寻找匹配(可重叠)
}
}
|
- 如果不允许重叠匹配:
j = P[j] 改为 j = 0 - 时间复杂度缩短至 $O(n)$
P 数组预处理(next 数组)
P[j] 表示:当匹配到 B 数组的第 j 个字母而第 j+1 个字母不能匹配时,新的 j 最大是多少。因此 P[1] = 0。
创建 P 数组——自己和自己匹配即可:
1
2
3
4
5
6
7
8
9
| void pre() {
P[1] = 0;
int j = 0;
for (int i = 1; i <= m; i++) {
while (j > 0 && B[j + 1] != B[i + 1]) j = P[j];
if (B[j + 1] == B[i + 1]) j++;
P[i + 1] = j; // 每趟循环求的是 i+1 位置的值
}
}
|
要点:
- B 串自我匹配
- 计算匹配长度
示例:最长公共前后缀
有两个字符串 S1 和 S2,要求找出 S1 的一个前缀同时是 S2 的一个后缀,输出最长的及长度。
例如 S1 = “riemann”,S2 = “marjorie” → “rie” 为最长(长度 3)。
解法:直接在二者中间加一个任意分隔符后使用 KMP 算法求解即可找到最大前后缀。
五、矩阵快速幂
引入
一个 01 组成字符串,任何子串不能包含 “101” 和 “111”,求满足要求的长度为 L($L \leq 10^8$)的字符串一共有多少,结果对 $10^9+7$ 取模。
递推公式:$f(n) = f(n-1) + f(n-3) + f(n-4)$
使用场景:递推级 n 很大时用于快速求幂。
普通矩阵乘法
1
2
3
4
| for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
c[i][j] = c[i][j] + a[i][k] * b[k][j];
|
但 n 比较大时,b 通过列访问,每次需要跳跃步长 n,缓存命中率低。以下是大幅提速的改进方法,调换了 j 和 k 顺序:
1
2
3
4
| for (int i = 0; i < n; i++)
for (int k = 0; k < n; k++)
for (int j = 0; j < n; j++)
c[i][j] = c[i][j] + a[i][k] * b[k][j];
|
此时 k 变化最快,b[k][j] 和 a[i][k] 同为行遍历,大幅提升缓存命中率。
快速幂 + 矩阵乘法
快速幂模板:
1
2
3
4
5
6
7
8
9
| int pow_mod(int a, int n) {
int ans = 1;
while (n) {
if (n & 1) ans = ans * a;
a = a * a;
n >>= 1;
}
return ans;
}
|
使用时要注意求模版本和开 long long。
核心:斐波那契与矩阵
$f[0] = 0$,$f[1] = 1$,$f[n] = f[n-1] + f[n-2]$,求 $f[k]$,结果对 $10^9+7$ 取余。
$$\begin{bmatrix} f[n] \\\\ f[n-1] \end{bmatrix} = \begin{bmatrix} 1 & 1 \\\\ 1 & 0 \end{bmatrix} \begin{bmatrix} f[n-1] \\\\ f[n-2] \end{bmatrix}$$设 $C(n) = \begin{bmatrix} f[n] \\ f[n-1] \end{bmatrix}$,$B = \begin{bmatrix} 1 & 1 \\ 1 & 0 \end{bmatrix}$,则有:
$$C(n) = B \times C(n-1) = B^{\,n-1} \times C(1)$$矩阵如何构造?
对于形如 $f(n) = a \cdot f(n-1) + b \cdot f(n-2)$ 的递推公式:
如 $f(n) = 3 \cdot f(n-1) + 5 \cdot f(n-3) + 9 \cdot f(n-4)$:
$$B = \begin{bmatrix} 3 & 0 & 5 & 9 \\\\ 1 & 0 & 0 & 0 \\\\ 0 & 1 & 0 & 0 \\\\ 0 & 0 & 1 & 0 \end{bmatrix} \qquad C(n) = \begin{bmatrix} f[n] \\\\ f[n-1] \\\\ f[n-2] \\\\ f[n-3] \end{bmatrix}$$带常数项如 $f(n) = a \cdot f(n-1) + b \cdot f(n-3) + c$:
$$\begin{bmatrix} f[n] \\\\ f[n-1] \\\\ f[n-2] \\\\ c \end{bmatrix} = \begin{bmatrix} a & 0 & b & 1 \\\\ 1 & 0 & 0 & 0 \\\\ 0 & 1 & 0 & 0 \\\\ 0 & 0 & 0 & 1 \end{bmatrix} \cdot \begin{bmatrix} f[n-1] \\\\ f[n-2] \\\\ f[n-3] \\\\ c \end{bmatrix}$$结合前缀和
$T[0] = T[1] = T[2] = 1$,$T[n] = T[n-1] + T[n-2] + T[n-3]$($n \geq 3$)。
给定 a 和 b(均在 $10^9$ 范围内),求 $(T[a] + T[a+1] + \cdots + T[b]) \bmod (10^9+7)$。
难点:要求前缀和 $S[b] - S[a-1]$,转化为求 $S[n]$:
$$\begin{bmatrix} S[n] \\\\ T[n] \\\\ T[n-1] \\\\ T[n-2] \end{bmatrix} = \begin{bmatrix} 1 & 1 & 1 & 1 \\\\ 0 & 1 & 1 & 1 \\\\ 0 & 1 & 0 & 0 \\\\ 0 & 0 & 1 & 0 \end{bmatrix} \cdot \begin{bmatrix} S[n-1] \\\\ T[n-1] \\\\ T[n-2] \\\\ T[n-3] \end{bmatrix}$$具体实现代码
朴素矩阵乘法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| struct matrix {
int p[11][11];
};
matrix mul(matrix a, matrix b) {
matrix ans;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
ans.p[i][j] = 0;
for (int i = 1; i <= n; i++)
for (int k = 1; k <= n; k++)
for (int j = 1; j <= n; j++) {
ans.p[i][j] += a.p[i][k] * b.p[k][j] % 9973;
ans.p[i][j] %= 9973;
}
return ans;
}
|
矩阵快速幂:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| matrix ksm(matrix a, int k) {
matrix ans;
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
ans.p[i][j] = 0;
for (int i = 1; i <= n; i++)
ans.p[i][i] = 1;
while (k > 0) {
if (k % 2 == 1) ans = mul(ans, a);
a = mul(a, a);
k /= 2;
}
return ans;
}
|
六、数论基础 — 逆元
欧几里得算法(辗转相除法)
1
2
3
| int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}
|
扩展欧几里得算法(贝祖定理)
$ax + by = \gcd(a, b) = d$
注意
贝祖定理证明:
$b \cdot x_0 + (a \bmod b) \cdot y_0 = d$
即 $b \cdot x_0 + (a - \lfloor a/b \rfloor \cdot b) \cdot y_0 = a \cdot y_0 + b \cdot (x_0 - \lfloor a/b \rfloor \cdot y_0)$
令 $x_1 = y_0$,$y_1 = x_0 - \lfloor a/b \rfloor \cdot y_0$,则得 $a \cdot x_1 + b \cdot y_1 = d = \gcd(a, b)$。得证。
1
2
3
4
5
6
7
8
| int ex_gcd(int a, int b, int &x, int &y) {
if (b == 0) { x = 1; y = 0; return a; }
int d = ex_gcd(b, a % b, x, y);
int tmp = x;
x = y;
y = tmp - (a / b) * y;
return d;
}
|
求 $Xa + Yb = 1$ 的非负整数 X 和整数 Y(扩展到 long long):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| #include <iostream>
using namespace std;
long long ex_gcd(long long a, long long b, long long &x, long long &y) {
if (b == 0) { x = 1; y = 0; return a; }
long long d = ex_gcd(b, a % b, x, y);
long long tmp = x;
x = y;
y = tmp - (a / b) * y;
return d;
}
void solve() {
long long a, b;
while (cin >> a >> b) {
long long x0, y0;
long long g = ex_gcd(a, b, x0, y0);
if (g != 1) {
cout << "sorry\n";
continue;
}
// 调整 X 到 [0, b-1],保证同余情况下最小
long long ans_x = (x0 % b + b) % b;
long long ans_y = (1 - ans_x * a) / b;
cout << ans_x << " " << ans_y << endl;
}
}
|
线性同余方程
$ax \equiv k \pmod b$,等价于 $ax + by = k$。
定理:对于未知量 x 有解当且仅当 $\gcd(a, b) \mid k$(k 是 gcd 的倍数)。
推论:若 $ax \equiv 1 \pmod b$ 有解,则必须 $\gcd(a, b) = 1$。此时 x 的解称为 a 模 b 的逆,所有解模 b 同余。
注意
如何确保求得的 x 是最小正整数解:x = (x % b + b) % b(再取模一次)。
费马小定理
作用:欧拉定理的特殊情况。
$a^{p-1} = a \cdot a^{p-2} \equiv 1 \pmod p$
所以在模 p 条件下,整数 a 的逆元是 $a^{p-2}$。
提示
费马小定理 + 快速幂 绑定运算,注意用 long long。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| const int MOD = 1e9 + 7;
// 快速幂
long long quick_pow(long long base, long long exp) {
long long res = 1;
base %= MOD;
while (exp > 0) {
if (exp & 1) res = (res * base) % MOD;
base = (base * base) % MOD;
exp >>= 1;
}
return res;
}
// 求逆元:x^(MOD-2) % MOD
long long inv(long long x) {
return quick_pow(x, MOD - 2);
}
|
应用示例(等比数列取模):
1
2
3
| SUM(k) % P = k * (k^m - 1) / (k - 1) % P
= k * (k^m - 1) * (k-1)^(-1) % P
= (k * (k^m - 1) % P) * ((k-1)^(P-2) % P) % P
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| void solve() {
int n, m;
while (cin >> n >> m) {
long long sum = 0;
for (int k = 1; k <= n; k++) {
if (k == 1) {
sum = (sum + m) % MOD;
} else {
long long num = k * (quick_pow(k, m) - 1) % MOD;
long long dev_inv = inv(k - 1);
long long tmp_sum = (num * dev_inv) % MOD;
sum = (sum + tmp_sum) % MOD;
}
}
cout << sum << endl;
}
}
|
线性求逆元
记 i 的逆元为 $i^{-1}$,设 $p = k \cdot i + r$。
则有 $k \cdot i + r \equiv 0 \pmod p$
同时乘 r 和 i 的逆元:
$$k \cdot r^{-1} + i^{-1} \equiv 0 \pmod p$$$$i^{-1} \equiv -k \cdot r^{-1} \pmod p$$其中 k = p / i(整除),r = p % i。
1
2
3
4
| inv[1] = 1;
for (int i = 2; i <= N; i++) {
inv[i] = (long long)(P - P / i) * inv[P % i] % P;
}
|
七、中国剩余定理 (CRT)
标准 CRT(模数两两互质)
定理:$m_1, m_2, \dots, m_n$ 是两两互质的正整数,对于任意 n 个整数 $a_1, a_2, \dots, a_n$,同余方程组 $x \equiv a_i \pmod{m_i}$ 有整数解,且在模 M 下解唯一。
构造解:$x = a_1 M_1 x_1 + a_2 M_2 x_2 + \cdots + a_n M_n x_n$
其中 $M_i = M / m_i$,$x_i$ 是线性同余方程 $M_i x_i \equiv 1 \pmod{m_i}$ 的一个解($M_i$ 和 $m_i$ 互质,必有解)。
以 $a_1 M_1 x_1$ 为例:$a_1 M_1 x_1 \equiv a_1 \pmod{m_1}$
注意
求线性同余方程组的解 x ⇒ n 次求 $x_i$
总结思路:
- $M = m_1 m_2 \cdots m_k$
- 对每个 i,令 $M_i = M / m_i$
- 由于 $\gcd(M_i, m_i) = 1$,存在 $t_i$ 满足 $M_i t_i \equiv 1 \pmod{m_i}$(用扩欧求解)
- 构造 $x = \sum_{i=1}^k a_i M_i t_i$
1
2
3
4
5
6
7
8
9
10
11
12
| int ChineseRemain(int n) {
int i, Mi, xi, yi, d, ans = 0;
M = 1;
for (i = 1; i <= n; i++) M *= m[i];
for (i = 1; i <= n; i++) {
Mi = M / m[i];
d = ex_gcd(Mi, m[i], xi, yi); // 求得 xi
ans = (ans + Mi * xi * a[i]) % M;
}
return (ans + M) % M; // 求出通解
}
|
扩展 CRT(模数不互质)
重要
如果不两两互质呢?
N 个正整数的最小公倍数(LCM)。假设已求得前 i 个数的 LCM 是 K:
- 判断 K 是否为第 i+1 个数的倍数
- 是则得解
- 不是,在 K 上不断加 K 直到为第 i+1 个数的倍数
也就是说只能在最小公倍数基础上放大。
通过数学归纳法:
- 前 k-1 个方程构成方程组的解为 x,记 $M = \text{lcm}(m_1, m_2, \dots, m_{k-1})$,则 $x + i \cdot M$ 是前 k-1 个方程的通解
- 考虑第 k 个方程,求出整数 t 使 $x + t \cdot M \equiv a_k \pmod{m_k}$
- 等价于 $M \cdot t \equiv a_k - x \pmod{m_k}$,其中 t 为未知量
- 若有解,扩欧可求出
- n 次扩欧后,最终求解整个方程组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| int Ex_crt() {
int M = m[1], x = a[1], t, y;
// M: 前 i-1 个模数的 LCM,x: 前 i-1 个方程的解
for (int i = 2; i <= n; ++i) {
int Mi = m[i];
int c = a[i] - x; // 对于第 i 个数,减掉 x 后求 t*M
int d = Ex_gcd(M, Mi, t, y); // t → d
if (c % d) return -1; // c 不能整除 d,无整数解
c /= d; Mi /= d;
t = (t * c % Mi + Mi) % Mi; // t 成为最小整数解
int lcm = M * Mi;
x = (M * t % lcm + x) % lcm;
M = lcm; // 新的 x 和 M 为下一趟循环做准备
}
return x == 0 ? M : x;
}
|
八、最短路径 — Dijkstra 堆优化
问题引入
Dijkstra 算法
从起点开始逐步扩展已知最短路径的节点集合。按照最短路径长度递增的次序,依次求得原点到其余各点的最短路径。
- 先求——最短的最短路径
- 再求——第二短的最短路径(直达 / 途经第一短后的二次转移)
重要
最重要的是每一趟都求一次最短路,从起点开始选择距离起点最近的未确定节点标记最短路径已确定。
以及松弛操作:每次通过选中的最短节点更新邻接节点的距离,为下次更新做准备。最后重复到所有节点确定。
算法步骤:
- 初始化:起点距离设为 0,其他节点设为 ∞,所有节点标记为未访问
- 迭代过程:从未访问节点中选择距离最小的节点 u,标记 u 为已访问,对 u 的每个邻接节点 v 进行松弛:如果
dist[u] + w(u,v) < dist[v],则更新 dist[v] - 终止条件:所有节点都被访问,或目标节点被访问
注意:Dijkstra 不能有负权边,否则会破坏无后效性。
朴素实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| #include <bits/stdc++.h>
using namespace std;
#define inf 0x7FFFFFFF
#define M 201
int Map[M][M], Dist[M], vis[M];
int main() {
int n, m, i, a, b, dis, now, Min, next, targe;
while (scanf("%d%d", &n, &m) == 2) {
for (i = 0; i < n; i++) {
vis[i] = 1;
Dist[i] = inf;
for (int j = 0; j < n; j++)
Map[i][j] = inf;
}
while (m--) {
scanf("%d%d%d", &a, &b, &dis);
Map[a][b] = min(Map[a][b], dis); // 处理重边
Map[b][a] = Map[a][b];
}
scanf("%d%d", &now, &targe);
Dist[now] = 0;
vis[now] = 0;
while (now != targe) { // O(n²) 复杂度
Min = inf;
for (i = 0; i < n; i++) {
if (Map[now][i] != inf)
Dist[i] = min(Dist[i], Map[now][i] + Dist[now]);
if (vis[i] && Dist[i] < Min) {
next = i;
Min = Dist[i];
}
}
if (Min == inf) break;
now = next;
vis[now] = 0;
}
if (Dist[targe] == inf) puts("-1");
else printf("%d\n", Dist[targe]);
}
return 0;
}
|
警告
理论表示:dist[k] = min(dist[i] + map[i][k])
实际:dist[k] = min(dist[k], dist[u] + map[u][k])
$O(n^2)$ 复杂度,$N = 10^5$ 就容易 TLE 了。
堆优化:链式前向星 + 优先队列
邻接表的数组实现(链式前向星)
有这样一个图,用邻接表表示如下:
1
2
3
4
| 顶点 1: -> (4, 9) -> (2, 5) -> (3, 7)
顶点 2: -> (4, 6)
顶点 3: -> (空)
顶点 4: -> (3, 8)
|
表头数组保存第一条边指向点,使用前插法来实时更新。
注意
邻接表对于稀疏数据来说更为合适。邻接矩阵判断是否有边要逐个判断,而邻接表可以直接通过 head 数组是否为 0 来判断。
堆优化后的 Dijkstra
优先队列维护 dist 的值从小到大,避免每次从 n 个节点找一个最优解。用小根堆实现,时间复杂度为 O(E log E)。
注意
小根堆:优先队列每次出队优先级最高元素。小根堆永远保持根节点小于子节点,插入和删除最小的时间复杂度为 O(log n)。
| 优先队列操作 | 小根堆实现 |
|---|
| 插入元素 | 堆尾插入 + 向上调整 |
| 取出最小元素 | 删除堆顶 + 向下调整 |
| 查看最小元素 | 返回 heap[1] |
| 判空 | 检查堆大小是否为 0 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| #include <bits/stdc++.h>
#define INF 2147483647
using namespace std;
int n, m, s;
int cnt, head[100005];
int dist[100005], vis[100005];
struct Edge {
int to, dis, next;
} edge[200005];
void Add_edge(int from, int to, int w) {
edge[++cnt].to = to;
edge[cnt].dis = w;
edge[cnt].next = head[from];
head[from] = cnt;
}
struct node {
int id, dis;
bool operator < (const node &a) const {
return a.dis < dis; // 小根堆:按距离最小优先
}
};
void Dijkstra() {
priority_queue<node> q;
q.push(node{s, 0});
for (int i = 1; i <= n; i++) dist[i] = INF;
dist[s] = 0;
while (!q.empty()) {
node a = q.top(); q.pop();
int now = a.id;
if (vis[now]) continue; // 关键优化:已确定最短则跳过
vis[now] = 1;
for (int i = head[now]; i; i = edge[i].next) {
int j = edge[i].to;
if (dist[now] + edge[i].dis < dist[j]) {
dist[j] = dist[now] + edge[i].dis;
q.push(node{j, dist[j]});
}
}
}
}
int main() {
cin >> n >> m >> s;
for (int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w;
Add_edge(u, v, w);
// 无向图加反向边:Add_edge(v, u, w);
}
Dijkstra();
for (int i = 1; i <= n; i++) {
if (dist[i] == INF) cout << "INF ";
else cout << dist[i] << " ";
}
cout << endl;
return 0;
}
|
加边的策略:一直往前加并更新 head,edge 保存了边的链表:
1
2
3
4
5
6
7
8
9
10
11
12
| 以顶点1为例,假设有边:1→2(权5), 1→3(权3), 1→4(权7)
head[1] = 3 // 指向最新加入的边(编号3)
│
▼
┌─────┐ ┌─────┐ ┌─────┐
│edge3│ → │edge2│ → │edge1│
│to:4 │ │to:3 │ │to:2 │
│dis:7│ │dis:3│ │dis:5│
│next:2│ │next:1│ │next:0│ ← 0表示结束
└─────┘ └─────┘ └─────┘
编号3 编号2 编号1(最先加入)
|
同一个节点为什么会被多次入堆?
因为 Dijkstra 在松弛过程中,每次发现更短路径时,会把 (节点, 新距离) 入堆。
| 步骤 | 堆内容 (id, dist) | 弹出 | 操作 |
|---|
| 初始 | (1, 0) | - | dist[1] = 0 |
| 1 | (1, 0) | 弹出 1 | dist[2]=5 入堆(2,5);dist[3]=2 入堆(3,2) |
| 2 | (3,2), (2,5) | 弹出(3,2) | vis[3]=1;dist[2] 从 5 更新到 4,入堆(2,4) |
| 3 | (2,4), (2,5) | 弹出(2,4) | vis[2]=1,正常处理 |
| 4 | (2,5) | 弹出(2,5) | vis[2]=1,触发 continue 跳过 |
关键点:
- 节点 2 被入了两次堆:先
(2,5),后 (2,4) - 当
(2,4) 弹出处理后,vis[2] 被标记为 1 - 之后
(2,5) 弹出时发现 vis[2] 已为 1,说明过时,直接跳过 - 正是因为 Dijkstra 按距离递增处理 + 优先队列,第一次弹出的定是最小更新
时间复杂度分析:松弛操作中每条边最多入一次堆,刚好一条最短路走到底就是 E 次。堆大小为 E,出入堆时间 O(log E)。总复杂度 O(E log E)。
不过如果是稠密图的话还是老实写朴素 Dijkstra 吧。
九、最短路径扩展 — Floyd / Bellman-Ford / SPFA
基于链式前向星的图遍历
回顾链式前向星遍历方式:
1
2
3
4
5
| for (int i = 1; i <= n; i++) {
for (int k = head[i]; k; k = edge[k].next) {
// edge[k] 即为从 i 出发的一条边
}
}
|
BFS 遍历:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| void bfs(int start) {
queue<int> q;
vis[start] = 1;
q.push(start);
while (!q.empty()) {
int u = q.front(); q.pop();
cout << u << " ";
for (int i = head[u]; i != 0; i = edge[i].next) {
int v = edge[i].to;
if (!vis[v]) {
vis[v] = 1;
q.push(v);
}
}
}
}
|
DFS 遍历:
1
2
3
4
5
6
7
8
9
| void dfs(int u) {
vis[u] = 1;
cout << u << " ";
for (int i = head[u]; i != 0; i = edge[i].next) {
int v = edge[i].to;
if (!vis[v]) dfs(v);
}
}
|
Floyd 算法(插点法,经典 DP)
解决多源最短路径问题(所有点到所有点)。
核心代码:
1
2
3
4
5
| for (k = 1; k <= n; k++) // 插入点 k 在外层循环(很关键)
for (i = 1; i <= n; i++) // 起点
for (j = 1; j <= n; j++) // 终点
if (dis[i][j] > dis[i][k] + dis[k][j])
dis[i][j] = dis[i][k] + dis[k][j];
|
思想:暴力枚举从 i 到 j 只经过前 k 个点的最短路径。
i 到 j 最短距离无非两种:
dp[i][k] 和 dp[k][j] 分别是 i 到 k 和 k 到 j 的最短距离,查完所有 k 后 dp[i][j] 必然是 i 到 j 的最短距离。
特点:简单粗暴,易于实现,甚至可以解决负权。时间复杂度 $O(V^3)$。
Bellman-Ford 算法
解决单源最短路径问题(单点到所有点)。
1
2
3
4
| for (k = 1; k <= n - 1; k++) // n-1 轮松弛
for (int i = 1; i <= m; i++) // m 条边
if (dis[v[i]] > dis[u[i]] + w[i])
dis[v[i]] = dis[u[i]] + w[i];
|
更清晰的写法:
1
2
3
4
| for (int i = 1; i <= n - 1; i++)
for (auto [u, v, w] : edges)
if (dist[u] + w < dist[v])
dist[v] = dist[u] + w;
|
为什么是 n-1 轮?
- 最短路径最多包含 n-1 条边(无环情况下)
- 每轮至少确定一层的距离
- n-1 轮后一定能得到所有最短路径
提示
小优化:不一定需要 n-1 轮松弛。
特点:简洁并且可以解决负权、负环问题。
负环检测:
1
2
3
4
| flag = 0;
for (int i = 1; i <= m; i++)
if (dis[v[i]] > dis[u[i]] + w[i]) flag = 1;
if (flag == 1) // 有负环
|
SPFA — Bellman-Ford 的队列优化
基本思想:每次仅对最短路径发生变化的点的相邻边执行松弛操作。
方案:队列维护。
具体操作:
- 起点加入队列,松弛和起点相连的所有边。若松弛成功且该点不在队列中,入队
- 依次取出队列中的每一个点松弛直到队列空
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| void spfa(int u) {
q.push(u);
vis[u] = 1; // 注意:vis 判断是否在队列中
while (!q.empty()) {
int x = q.front(); q.pop();
vis[x] = 0; // 移除后允许再次入队
for (int i = head[x]; i; i = edge[i].next) {
int y = edge[i].to;
if (dist[x] + edge[i].dis < dist[y]) {
dist[y] = dist[x] + edge[i].dis;
if (!vis[y]) {
vis[y] = 1;
q.push(y);
}
}
}
}
}
|
最短路径算法总结
时间复杂度对比:
1
2
3
4
| 速度(快 → 慢)
堆 Dijkstra > SPFA(平均) > 朴素 Dijkstra > Floyd / Bellman-Ford(最坏)
O((V+E)log V) O(E) O(V²) O(V³) / O(V×E)
|
算法选择指南:
| 场景 | 推荐算法 | 理由 |
|---|
| 稠密图、V ≤ 2000、无负权 | 朴素 Dijkstra | O(V²) 比堆优化常数小 |
| 稀疏图、大 V(10⁵)、无负权 | 堆优化 Dijkstra | O((V+E) log V) |
| V ≤ 400、需要所有点对 | Floyd | 实现简单,V³ 可接受 |
| 边数少、有负权但无负环 | SPFA | 平均很快,代码不长 |
| 需要保证最坏情况稳定、有负权 | Bellman-Ford | 不怕被卡数据 |
| 必须检测负环 | Bellman-Ford / SPFA | 两者均可检测 |
速查口诀:
- 无负权、稀疏图 → 堆优化的 Dijkstra
- 无负权、稠密图 → 朴素 Dijkstra
- 全源最短路、小图 → Floyd
- 有负权、要稳定 → Bellman-Ford
- 有负权、要速度 → SPFA(可能被卡)
map 应用示例
有时出现"杭州"等不便构建邻接矩阵的字符串类型输入,用 map 映射:
1
2
3
4
5
6
7
8
9
10
11
12
13
| map<string, int> m1;
for (int i = 1; i <= n; i++) {
string s; cin >> s;
m1[s] = i;
}
cin >> m;
while (m--) {
string s1, s2;
int num;
cin >> s1 >> num >> s2;
int from = m1[s1], to = m1[s2];
dis[from][to] = num;
}
|
本文所有代码模板已整理为独立板子速查表,方便用时直接复制使用:竞赛代码板子速查 →